
type
status
date
slug
summary
tags
category
Property
Nov 30, 2023 02:46 PM
icon
password
属性
属性 1
描述
Origin
URL
数模电CMOS的特点同步逻辑和异步逻辑?同步电路和异步电路的区别:时序设计的实质:触发器建立时间和保持时间的概念,为什么要满足触发器的建立时间和保持时间?什么是亚稳态,为什么会产生亚稳态,减少亚稳态的方法?系统最高速度计算(最快时钟频率)和流水线设计思想:跨时钟域同步方法1.单比特2.多bit传输锁存器(latch)和触发器(flip-flop)区别?数字电路功耗1.Dynamic Power Consumption 动态功耗2.Static Power Consumption 静态功耗3.Principles for Power Reduction 降低功耗的原则放大电路有几种工作状态竞争与冒险 Verilog同步复位和异步复位的区别,体现在verilog代码中是什么样子 状态机分类状态机二段式和三段式的区别HDL语言的层次概念?SystemVerilog定宽数组、动态数组、关联数组、队列各自特点和使用array中,pack和unpack的区别 变量类型、四值逻辑和二值逻辑区别及使用 Wire、 reg和 logic有什么区别 多线程fork join/ fork join _ any / fork join_none的用法差异多线程的同步调度方法①事件(event)②旗语(semaphore)③信箱(mailbox)Task和function的区别TB中使用interface和clocking block的好处OPP(面向对象)的特性面向对象编程的优势谈谈SV中的class 虚方法的作用 Virtual 在class中为啥要用virtual interface 而不能用interface事件的触发约束的几种形式 随机时,如果想把constraint里的某个数据不让它随机,使用什么方法 Rand 和Randc的区别有两个变量rand A, rand B, 怎么控制b先随机 如何关闭约束get_next_item()和try_next_item()有什么区别Break;continue;return的含义,return之后,function里剩下的语句会执行吗简述深拷贝和浅拷贝用过断言嘛?写一个断言,a为高的时候,b为高,还有a为高的时候,下一个周期b为高立即断言和并行断言Assertion嘛,Assertion分几种?简述一下Assertion的用法UVM方法学简述UVM的工厂机制Uvm_component_utils有什么作用如果环境中有两个config_db set,哪个有效?通过工厂进行覆盖有什么要求?你了解uvm的factory机制和callback机制嘛Callback介绍一下field_automation机制和objection机制UVM从哪里启动phase机制以及执行顺序举例说明UVM组件中常用的方法,各种phase关系,phase机制作用接口怎么传递到环境中(通过config_db的方式)如何在driver中使用interface,为什么UVM的优势,为什么要用UVM?说一下component和object的区别,item是component还是objectUVM树形结构UVM验证环境的组成uvm验证环境的构成、uvm每个组件的作用、agent的作用Virtual sequencer 和sequencer的区别平台往里边输入数据的话怎么输入sequence,sequence,sequencer,driver之间的通信Sequence和item(uvm_sequece,uvm_sequence_item)以及sequence的分类Sequence和sequencer的关系Sequencer的仲裁特性(set_arbitration)及锁定机制(lock和grab) Virtual sequence和virtual sequencer中virtual含义为什么会有sequence、sequencer以及driver,为什么要分开实现,这样做的好处是什么?启动Sequence的方法组件之间的通信机制,analysis port和其它的区别UVM各个component之间的通信机、UVM TILM通信,解释一下TLM怎么用UVM组件的通信方式TLM的接口分类和用法,peek和get的差异Analysis port是否可以不连或者连多个impport你所搭建的验证平台为什么要用RAL(寄存器)前门访问和后门访问的区别 后门访问的路径怎么配置如果寄存器的地址不匹配的错误怎么测试出来 寄存器模型的常规方法(期望值、镜像值、真实值)寄存器模型里,update()和mirror()方法的作用Prediction的分类(自动预测和显式预测)寄存器怎么配置,adapter怎么集成对UVM验证方法学的理解UVM有什么优缺点:请谈一下UVM的验证环境结构,各个组件间的关系其他问题IC设计流程也即ASIC设计流程代码覆盖率、功能覆盖率和断言覆盖率的区别项目中会考虑哪些coverage Coverage一般不会直接达到100%,当你发现condition未cover到的时候,你该怎么做?covergroup在哪里定义,哪里例化,有哪些,分别怎么做采样,根据什么来写 Function coverage和 Code coverage的区别,以及他们分别对项目的含义你在做验证时的流程是怎么样的,你是怎么做的。你在进行验证的过程中,碰到过什么难点,重点是什么呢?定向测试和随机测试的区别,为什么现在越来越多的随机测试?形式验证如何保证验证的完备性?触发器和锁存器的区别怎么编写测试用例?验证流程,验证环境怎么搭AMBA总线中AHB/APB/AXI协议的区别a[*3]、a[->3]和a[=3]区别你发现过哪些验证过程中的 bug,如何发现的,怎么解决的?你的验证环境是什么?目录结构是什么样的ASIC芯片设计流程iC设计前端到后端的流程和EDA工具?参考资料const (ref)、input、output、inout分别是什么意思?全局变量和局部变量的作用域是什么,静态变量和动态变量的区别是什么?package的作用使用,使用package和include有什么区别?什么是OOP,三大要素是什么,三大要素在SV中分别使用什么来实现的,使用OOP有什么好处,SV中有重载吗,覆盖和重载的区别是什么SV的覆盖率如何声明,如何采集覆盖率,bin的数量如何确定,交叉覆盖率的作用是什么,ignore和illegal的bin如果触发了有什么区别SV的仿真调度机制是什么样的?
数模电
CMOS的特点
CMOS反相器
通常会把MOS管做成PMOS(P表示Positive)和NMOS(N表示Negative)两种类型,这两种管子是互补的,合起来称为CMOS(C表示Complementary,即互补)。

- 若In输入0,NMOS的Gate是0,NMOS处于关闭状态;PMOS的Gate经过反相器(图中小圆圈)是1,PMOS处于打开状态;此时Out与PMOS的Source端状态一样,即Out被拉至VDD,输出1。
- 若In输入1,NMOS是打开状态,PMOS是关闭状态,Out与NMOS的Drain端状态一样,即Out被拉至GND,输出0。
- 综上,该逻辑实现的是一个反相器。
同步逻辑和异步逻辑?
同步逻辑是时钟之间固有的因果关系,异步逻辑是各时钟之间没有固定的因果关系。
同步时序逻辑电路的特点:各触发器的时钟端全部连接在一起,并接在系统时钟端,只有当时钟脉冲到来时,电路的状态才能改变。改变后的状态将一直保持到下一个时钟脉冲的到来,此时无论外部输入x有无变化,状态中的每个状态都是稳定的。
异步时序逻辑电路的特点:电路中除可以使用带时钟的触发器外,还可以使用不带时钟的触发器和延迟元件作为存储元件,电路中没有统一的时钟,电路状态的改变由外部输入的变化直接引起。
同步电路和异步电路的区别:
同步电路:存储电路中所有触发器的时钟输入端都按同一个时钟脉冲源,因而所有触发器的状态的变化都与所加的时钟脉冲信号同步。
异步电路:电路没有统一的时钟,有些触发器的时钟输入端与时钟脉冲源相连,只有这些触发器的状态变化与时钟脉冲同步,而其他的触发器的状态变化不与时钟脉冲同步。
时序设计的实质:
时序设计的实质就是满足每一个触发器的建立/保持时间的要求。
触发器建立时间和保持时间的概念,为什么要满足触发器的建立时间和保持时间?
答:建立时间(setup time):是指在触发器的时钟信号上升沿到来以前,数据稳定不变的时间,如果建立时间不够,数据将不能在这个时钟上升沿被打入触发器。
保持时间(hold time):是指在触发器的时钟信号上升沿到来以后,数据稳定不变的时间,如果保持时间不够,数据同样不能被打出触发器。
如果不满足建立和保持时间,触发器将进入亚稳态,进入亚稳态后触发器的输出将不稳定,在0和1之间变化,这时需要经过一个恢复时间,其输出才能稳定,但稳定后的值并不一定是你的输入值。
什么是亚稳态,为什么会产生亚稳态,减少亚稳态的方法?
(1)亚稳态是指触发器无法在某个规定的时间段内到达一个可以确认的状态。
(2)亚稳态一般发生在跨时钟传输、异步信号采集中以及复位电路中。 在同步系统中,输入总是与时钟同步,因此寄存器的setup time和hold time是满足的,一般情况下是不会发生亚稳态情况的。
1、跨时钟域信号传输
产生:在跨时钟域信号传输时,由于源寄存器时钟和目的寄存器时钟相移未知,所以源寄存器数据发出数据,数据可能在任何时间到达异步时钟域的目的寄存器,所以无法保证满足目的寄存器Tsu和Th的要求,从而出现亚稳态。
消除:对异步信号进行同步处理;如添加两级D触发器、采用握手进行交互等。
使用两级触发器来使异步电路同步化的电路其实叫做“一位同步器”。只能用来对一位异步信号进行同步。两级触发器可防止亚稳态传播的原理:假设第一级触发器的输入不满足其建立保持时间,它在第一个脉冲沿到来后输出的数据就为亚稳态,那么在下一个脉冲沿到来之前,其输出的亚稳态数据在一段恢复时间后必须稳定下来,而且稳定的数据必须满足第二级触发器的建立时间,如果都满足了,在下一个脉冲沿到来时,第二级触发器将不会出现亚稳态,因为其输入端的数据满足其建立保持时间。同步器有效的条件:第一级触发器进入亚稳态后的恢复时间+第二级触发器的建立时间<=时钟周期。
更确切地说,输入脉冲宽度必须大于同步时钟周期与第一级触发器所需的保持时间之和。最保险的脉冲宽度是两倍同步时钟周期。所以,这样的同步电路对于从较慢的时钟域来的异步信号进入较快的时钟域比较有效,对于进入一个较慢的时钟域,则没有作用。
2、异步信号采集
产生:在异步信号采集中,由于异步信号可以在任意时间点到达目的寄存器,所以也无法保证满足目的寄存器Tsu和Th的要求,从而出现亚稳态。
消除:采用FIFO对跨时钟域数据通信进行缓冲设计;
3、异步复位电路
产生:在异步复位电路中,复位信号的释放时间不定,难以保证满足恢复时间(Recovery Time)以及去除时间(Removal Time),从而出现亚稳态。
消除: 对复位电路采用异步复位、同步释放方式处理。
系统最高速度计算(最快时钟频率)和流水线设计思想:
同步电路的速度是指同步系统时钟的速度,同步时钟愈快,电路处理数据的时间间隔越短,电路在单位时间内处理的数据量就愈大。
假设Tco是触发器的输入数据被时钟打入到触发器到数据到达触发器输出端的延时时间 (Tco=Tsetpup+Thold); Tdelay是组合逻辑的延时; Tsetup是D触发器的建立时间。
假设数据已被时钟打入D触发器,那么数据到达第一个触发器的Q输出端需要的延时时间是Tco,经过组合逻辑的延时时间为Tdelay,然后到达第二个触发器的D端,要希望时钟能在第二个触发器再次被稳定地打入触发器,则时钟的延迟必须大于Tco+Tdelay+Tsetup,也就是说最小的时钟周期Tmin=Tco+Tdelay+ Tsetup,即最快的时钟频率Fmax=1/Tmin。FPGA开发软件也是通过这种方法来计算系统最高运行速度Fmax。因为Tco和Tsetup是由具体的器件工艺决定的,故设计电路时只能改变组合逻辑的延迟时间Tdelay,所以说缩短触发器间组合逻辑的延时时间是提高同步电路速度的关键所在。
由于一般同步电路都大于一级锁存,而要使电路稳定工作,时钟周期必须满足最大延时要求。故只有缩短最长延时路径,才能提高电路的工作频率。可以将较大的组合逻辑分解为较小的N块,通过适当的方法平均分配组合逻辑,然后在中间插入触发器,并和原触发器使用相同的时钟,就可以避免在两个触发器之间出现过大的延时,消除速度瓶颈,这样可以提高电路的工作频率。这就是所谓"流水线”技术的基本设计思想,即原设计速度受限部分用一个时钟周期实现,采用流水线技术插入触发器后,可用N个时钟周期实现,因此系统的工作速度可以加快,吞吐量加大。注意,流水线设计会在原数据通路上加入延时,另外硬件面积也会稍有增加。
跨时钟域同步方法
1.单比特
最简单的办法就是打两拍,就是所谓的两级DFF
1、有关系的时钟之间传单bit数据,理论上只需要源数据保持足够长的时间(clk2的两个周期)即可;
2、无关系的时钟之间传单bit数据,必须要使用同步器;
3、不管有无关系的时钟进行单bit传输,脉冲同步器都可以解决这个问题;
2.多bit传输
只能使用握手机制或者异步fifo;
低频采高频,为防止数据不丢失,应当让源数据变慢,多保持一些周期;
高频采低频则不需要,但是高频采低频得到的结果可能带有很多冗余。
所以就记住两级DFF和异步FIFO的使用基本上很多问题都可以解决。
对以一位的异步信号可以使用“一位同步器进行同步”(使用两级触发器),而对于多位的异步信号,可以采用如下方法:1:可以采用保持寄存器加握手信号的方法(多数据,控制,地址);2:特殊的具体应用电路结构,根据应用的不同而不同:3:异步FIFO。(最常用的缓存单元是DPRAM)
锁存器(latch)和触发器(flip-flop)区别?
电平敏感的存储器件称为锁存器。可分为高电平锁存器和低电平锁存器,用于不同时钟之间的信号同步。
有交叉耦合的门构成的双稳态的存储原件称为触发器。分为上升沿触发和下降沿触发。可以认为是两个不同电平敏感的锁存器串连而成。前一个锁存器决定了触发器的建立时间,后一个锁存器则决定了保持时间。
数字电路功耗
1.Dynamic Power Consumption 动态功耗
1.1、Charging and discharging capacitors 翻转功耗
管子的翻转,导致的管子的开和关形成的功耗!

- 升压可提高性能(CELL的延时会变短,transient 会变短,翻转频率可以跑的更高些),但同时功耗增加
- 温度升高时,功耗增加
- 从上述动态功耗公式可以看出,动态功耗和晶体管大小无关,和电压的平方成正比(Vdd2 ) ,和翻转率成正比(f ),和Vout接的负载有关系(CL )
Node Transition Activity and power 节点转换活动和功率

- 做工程的话最终用的还是推导的结论,即上图中红色框住的部分。从结论不难得出,功耗的Average主要与电压的平方、跟时钟频率有关系。
1.2、Short Circuit Currents 短路功耗
Short circuit path between supply rails during switching 开关导通瞬间的电源和地之间形成短路(eg:CMOS反相器两个管子同时导通的情形)

- 上图中的第二幅图,假设电压Vdd是5V,当电压是2.5V左右时,短路电流达到最大!
Minimizing Short-Circuit Power 最小化短路功耗

- 从上图不难看出,电源电压Vdd是决定短路功耗的一个重要因素。
2.Static Power Consumption 静态功耗
2.1、Leakage 漏电功耗
Leaking diodes and transistors 二极管和晶体管漏电(与地之间形成通路,不过电流很小)

- 器件本身的原因必然会产生漏电电流
- 要解决漏电功耗是把它的Sub-Threshold做一些变化,供应商会提供多种不同的库,不同的库Sub-Threshold不一样。Sub-Threshold高,频率会高一些,延时会短一些,对应的漏电功耗就越大。
3.Principles for Power Reduction 降低功耗的原则

- 降功耗最主要的是降电压,其次是减少反转率(如进行时钟门控),最后是减少电容!

放大电路有几种工作状态
三极管电路的三种状态是
1、放大状态:此时三极管的发射结处于正向偏置,集电结处于正向偏置。
2、截止状态:此时三极管的发射结处于方向偏置,集电结处于正向偏置。
3、饱和状态:此时三极管的发射结处于正向偏置,集电结处于反向偏置。
竞争与冒险
①竞争: 在组合电路当中,当某个输入变量具有两条以上的路径到达输出端的时候,由于每条路径上的延迟时间的不同,到达终点的时间就会有先有后,这一现象称作竞争。所以这是一个输入级的概念。
②冒险:组合逻辑电路中有两个输入信号A和B,当A、B同时向相反的逻辑电平跳变(A : 1—> 0 ; B : 0 —> 1),有可能导致输出端可能产生毛刺的现象,称为冒险。这是一个输出级概念。
③解决方法:
方法一:接入滤波电容
在输出端并接一个滤波电容Cf,可以将毛刺的幅度削弱至有效点平范围之下。
缺点:增加了输出电压波形的上升时间和下降时间,使波形变坏。适合对输出波形前后无严格要求的场合。
方法二:引入选通脉冲
设法得到一个与输入信号同步的选通脉冲,对这个脉冲的宽度和作用时间有严格要求。
方法三:增加冗余项
例如:Y = AB +A’C,在B=C=1的条件下,会产生竞争冒险。通过增加冗余项BC来消除。
由于BC=1,所以Y = AB +A’C + BC成立。
此时,无论A的状态如何变化,都不会引起竞争与冒险。
方法四:加blocking clock;
Verilog
同步复位和异步复位的区别,体现在verilog代码中是什么样子
如图所示

状态机分类
状态机可以分为Moore型状态机和Mealy型状态机,
Moore型状态机的输出只与当前状态机所处的状态有关,与当前输入无关。
Mealy型状态机的输出不仅与当前状态机所处的状态有关,也与当前输入有关。
由于Mealy型状态机的输出与输入有关,输出信号中很容易出现毛刺,所以在日常设计中一般采用Moore型状态机。


状态机二段式和三段式的区别
两段式状态机有两个always块: 一个采用时序电路描述状态的转移方式,即当前状态和协议状态的跳转。另一个采用组合逻辑电路来输出相应状态的数据。 三段式状态机有三个always块: 一个采用时序电路描述当前状态和协议状态的跳转。一个采用组合逻辑电路来描述下一状态的转移条件,第三个采用组合逻辑电路来输出相应状态的数据。
HDL语言的层次概念?
HDL语言是分层次的、类型的,最常用的层次概念有系统与标准级、功能模块级,行为级,寄存器传输级和门级。
系统级,算法级,RTL级(行为级),门级,开关级
SystemVerilog
定宽数组、动态数组、关联数组、队列各自特点和使用
- 队列:队列结合了链表和数组的优点,可以在一个队列的任何位置进行增加或者删除元素;
队列的使用方法:
insert,delete,push_back和pop_front。Push插入,pop取出。Front前边,back后边。如:q.insert(i,j )— 在固定位置i插入数 j; q.push_front(bask) — 前(后)插入;j=q.pop_back(front)—从后(前)取出给 j- 定宽数组:属于静态数组,编译时便已经确定大小。其可以分为压缩定宽数组和非压缩定宽数组:压缩数组是定义在类型后面,名字前面Bit [7:0][3:0] name; 非压缩数组定义在名字后面。bit[7:0] name [3:0];
- 动态数组:其内存空间在运行时才能够确定,使用前需要用new[]进行空间分配。
int dyn[];
initial begin
dyn = new[5];
end
- 关联数组:其主要针对需要超大空间但又不是全部需要所有数据的时候使用,类似于
hash,通过一个索引值和一个数据组成,索引值必须是唯一的。
array中,pack和unpack的区别
①非合并数组:如 bit [7:0] arry1[3];
存储方式:按[7:0] 8位存放,32位中没使用也会继续开辟新空间

②合并数据:如bit [3:0] [7:0] arry2;
存储方式:紧凑连续存放,32位不存放完不会开辟新空间
变量类型、四值逻辑和二值逻辑区别及使用

①二值逻辑只可以表示0和1;四值逻辑可表示0、1、x和z;
②二值逻辑仿真工具开辟的存储空间更小且其行为更接近真实的电路;使用四值逻辑是因为实际过程中会出现错误,如volition等从而出现x和z态来提示出错;
③二值逻辑的默认值是0;四值逻辑的默认值为x。
Wire、 reg和 logic有什么区别
①总结Verilog wire和reg的区别:
wire表示导线结构,reg表示存储结构。
wire使用assign赋值,reg赋值定义在always、initial、task或function代码块中。
wire赋值综合成组合逻辑,reg可能综合成时序逻辑,也可能综合成组合逻辑。
②总结SystemVerilog logic的使用方法:
单驱动时logic可完全替代reg和wire,除了Evan提到的赋初值问题。
多驱动时,如inout类型端口,使用wire。
多线程fork join/ fork join _ any / fork join_none的用法差异
Fork join :内部 begin end 块并行运行,直到所有线程运行完毕才会进入下一个
阶段。
Fork join_ any :内部 begin end 块并行运行,任意一个 begin end 块运行结束
就可以进入下一个阶段。
Fork join_ none :内部 begin end 块并行运行,无需等待可以直接进入下一个阶
段。
wait fork :会引起调用进程阻塞,直到它的所有子进程结束,一般用来确保所有
子进程(调用进程产生的进程,也即一级子进程)执行都已经结束。
disable fork :用来终止调用进程 的所有活跃进程, 以及进程的所有子进程。
多线程的同步调度方法
多线程之间同步主要由 mailbox、 event、 semaphore 三种进行一个通信交互。
①事件(event)
事件主要用于两个线程之间的一个同步运行,通过事件触发和事件等待进行两个线程间的运行同步。event可用于实现线程的同步,通过->操作符来触发事件,通过@和wait来等待事件。在这当中,@为边沿敏感型,可能出现因事件已经被触发而被阻塞住的情况,而wait(xx.triggered)则是电平敏感,如果当前事件已经被触发也不会被阻塞。使用 @(event) 或者 wait(event. trigger) 进行等待,->进行触发。不同的是触发会阻塞,而wait或者@等待不会阻塞。
②旗语(semaphore)
旗语主要是用于对资源访问的一个交互,通过key的获取和返回实现一个线程对资源的一个访问。使用put和 get函数获取返回key。一次可以多个。
③信箱(mailbox)
mailbox邮箱 :主要用于两个线程之间的数据通信,通过 put 函数和 get 函数还有 peek 函数进行数据的发送和获取。
在使用sv搭建验证环境时,mailbox的使用还是比较普遍,主要用于各个组件之间的通信(及信息传输)
Task和function的区别
函数可以调用另一个函数,但不能调用任务。任务可以调用任务,也可以调用函数。因此新手建议直接用任务。
函数总是在仿真时刻0就开始执行,任务可以非0时刻执行。
函数一定不能包括任何时延,事件或者时序控制声明语句。任务可以。
函数至少一个输入变量,也可以多个输入。任务可以没有或者多个输入、输出、双向变量。
函数只能返回一个值,函数不能有输出或者双向变量。任务不能返回值,但可以通过输出或者双向变量传递多个值。
TB中使用interface和clocking block的好处
interface是一组接口,用于对信号进行一个封装。像veriLog中每个信号进行连接,每一层我们都需要对信号进行定义,信号太多很容易出现人为错误,重用性不高。
采用interface接口进行封装,能简化代码,提高重用性。除此之外,interface还提供其他一些功能,用于测试平台与dut之间的同步和避免竞争。
Clocking block:在interface 内部定义的block块,可以使得信号保持同步,对于接口的采样和驱动有详细的操作,从而避免tb和dut竞争,减少信号竞争导致的错误。
采样提前,驱动落后,保证信号不会竞争。
OPP(面向对象)的特性
封装、继承和多态
封装:通过将一些数据和使用这些数据的方法封装在一个集合里,成为一个类。
继承:允许通过现有类去得到一个新的类,且其可以共享现有类的属性和方法。现有类叫做基类,新类叫做派生类或扩展类。
多态:得到扩展类后,有时我们会使用基类句柄去调用扩展类对象,这时候调用的方法如何准确去判断是想要调用的方法呢?通过对类中方法进行
virtual声明,这样当调用基类句柄指向扩展类时,方法会根据对象去识别,调用扩展类的方法,而不是基类中的。而基类和扩展类中方法有着同样的名字,但能够准确调用,叫做多态。面向对象编程的优势
- 易维护:采用面向对象思想设计的结构,可读性高,由于继承的存在,即使改变需求,那么维护也只是在局部模块,所以维护起来是非常方便和较低成本的。
- 质量高:在设计时,可重用现有的,在以前的项目的领域中已被测试过的类使系统满足业务需求并具有较高的质量。
- 效率高:在软件开发时,根据设计的需要对现实世界的事物进行抽象,产生类。使用这样的方法解决问题,接近于日常生活和自然的思考方式,势必提高软件开发的效率和质量。
- 易扩展:由于继承、封装、多态的特性,自然设计出高内聚、低耦合的系统结构,使得系统更灵活、更容易扩展,而且成本较低。
谈谈SV中的class
①验证证环境的不同组件其功能和所需要处理的数据内容是不相同的。不同环境的同一类型的组件其所具备的功能和数据内容是相似的。基于以上两点,验证世界的各个组件角色明确、功能分立,使用面向对象编程与验证世界的构建原则十分符合;
②class类:基本模块包括成员变量和方法。在Verilog中module也可以包含变量和方法,只不过它是“硬件盒子”,class是“软件盒子”。
③Verilog中没有句柄的概念,即只能通过层次化的索引方式A.B.sigx,而SV中的class通过句柄可以将对象的指针赋予其它句柄,使得操作更加灵活。
④与硬件域例如module、interface不同的是,在class中声明的变量其默认为类型为动态变量,即其声明周期在仿真开始后的某时间点开始到某时间点结束。在class中定义的方法默认类型是动态方法,也可以通过关键字static修改为静态方法。
虚方法的作用 Virtual
1)不使用virtual,父类句柄虽指向子类对象,但调用的仍是父类本身的函数
2)使用virtual,父类句柄指向子类对象,调用的是子类的函数
类似上述总结结论:
1)声明虚方法时,根据对象来决定调用
2)未声明虚方法时,根据句柄来决定调用
加了给父类的方法加了virtual后,不用担心使用的是父类还是子类的方法,最终都会执行子类方法。动态方法查找,会先查找子类中是否有同名的方法,子类中没有的话就执行父类中的该名字方法,子类中有就执行子类中的同名方法。
注意
- 在为父类定义方法时如果该方法日后可能会被覆盖或者继承那么应该声明为虚方法.
- 虚方法如果要定义,应该尽量定义在底层父类中。这是因为如果virtual是声明在类继承关系的中间层类中,那么只有从该中间类到其子类的调用链中会遵循动态查找,而最底层类到该中间类的方法调用仍然会遵循静态查找。
- 在父类中声明一次即可,虚方法通过virtual)声明,只需要声明一次即可。当然再次声明来表明该方法的特性也是可以的。虚方法的继承也需要遵循相同的参数和返回类型,否则,子类定义的方法须归为同名不同参的其它方法。
在class中为啥要用virtual interface 而不能用interface
Interface在编译阶段就要分配空间,而class是运行时是通过创建才会分配空间,所以不能在class里声明interface,必须加virtual把它声明成句柄,运行时再指向句柄。
事件的触发
用来触发事件时,使用->;用来等待事件使用@或者wait。
约束的几种形式
- 权重约束 dist:有两种操作符::=n 第一种表示每一个取值权重都是n, :/n 第二种表示每一个取值权重为n/num。

使用权重时,:= 和 :/ 区别
:=表示值范围内的每一个值的权重是相同的;如src dist {[1:3]:=60};1,2,3的权重都是60,概率均为60/180;
:/表示权重均分到值范围内的每一个值。dst dist {[1:3]:/60};1,2,3权重均分60,为20,概率为20/60.
- 条件约束 if else 和->(case):if else 就是和正常使用一样;->通过前面条件满足后可以触发后面事件的发生。

3.范围约束inside:inside{[min:max]};范围操作符,也可以直接使用大于小于符号进行,但是不可以连续使用,如 min<wxm<max 这是错误的


随机时,如果想把constraint里的某个数据不让它随机,使用什么方法
①如果只有少数几个变量需要修改,可以调用rand-mode();函数把这些变量设置为非随机数;如p.length.rand_mode(0);
p.length=42。
②p.constraint_mode(0);关闭随机约束块;(0);关闭,(1);打开
Rand 和Randc的区别
rand修饰符:rand修饰的变量,每次随机时,都在取值范围内随机取一个值,每个值被随机到的概率是一样的,就想掷骰子一样。
randc修饰符:randc表示周期性随机,即所有可能的值都取到过后,才会重复取值
有两个变量rand A, rand B, 怎么控制b先随机
可以加入把B加入到fork join中。如:
如何关闭约束
- 通过
constraint_mode(0)关闭默认范围的约束块
constraint_mode(1)是打开约束
- 可以用
soft关键字修饰特定的约束语句,这样既可以让变量在一般的情况下取默认值,也可以直接给变量赋默认值范围外的取值。
get_next_item()和try_next_item()有什么区别
get_next_item()是一个阻塞调用,直到存在可供驱动的sequence item为止,并返回指向sequence item的指针。
try_next_item()是非阻塞调用,如果没有可供驱动的sequence item,则返回空指针。
Break;continue;return的含义,return之后,function里剩下的语句会执行吗
break语句结束整个循环。
continue立即结束本次循环,继续执行下一次循环。
return语句会终止函数的执行并返回函数的值(如果有返回值的话)。return之后,function里剩下的语句不能执行,其是终止函数的执行,并返回函数的值。
简述深拷贝和浅拷贝


用过断言嘛?写一个断言,a为高的时候,b为高,还有a为高的时候,下一个周期b为高

立即断言和并行断言

Assertion嘛,Assertion分几种?简述一下Assertion的用法
Assertion可以分为立即断言和并发断言。
- 立即断言的话就是和时序无关,比如我们在对激励随机化时,我们会使用立即断言,如果随机化出错我们就会触发断言报错。
- 并发断言的话主要是用来检测时序关系的,由于在很多模块或者总线中,单纯使用覆盖率或者事务
check并不能完全检测多个时序信号之间的关系,但是并发断言却可以使用简洁的语言去监测,除此之外,还可以进行覆盖率检测。
并发断言的用法的话,主要是有三个层次:
序列
sequence编写,将多个信号的关系用断言中特定的操作符进行表示;属性
property的编写,它可以将多个sequence和多个property进行嵌套,外加上触发事件;assert的编写,调用property就可以。编写完断言后我们可以将它用在很多地方,比如DUT内部,或者在top层嵌入DUT 中,还可以在interface处进行编写,基本能够检测到信号的地方都可以进行断言检测。UVM方法学
简述UVM的工厂机制
Factory机制也叫工厂机制,其存在的意义就是为了能够方便的替换TB中的实例或者已注册的类型。一般而言,在搭建完TB后,我们如果需要对TB进行更改配置或者相关的类信息,我们可以通过使用factory机制进行覆盖,达到替换的效果,从而大大提高TB的可重用性和灵活性。
- 要使用factory机制先要进行:
- 将类注册到factory表中
- 创建对象,使用对应的语句 (type_id::create)
- 编写相应的类对基类进行覆盖。
Uvm_component_utils有什么作用
factory机制的实现被集成在了一个宏中:uvm_component_utils。
- 这个宏最主要的任务是,将字符串登记在
UVM内部的一张表中,这张表是factory功能实现的基础。只要在定义一个新的类时使用这个宏,就相当于把这个类注册到了这张表中。这样,factory机制可以实现:根据一个字符串自动创建一个类的实例,并且调用其中的函数(function)和任务(task),这个类的main_phase就会被自动调用。
如果环境中有两个config_db set,哪个有效?
UVM更高的层次更接近用户,为了让用户少和底层组件打交道,所以层次越高优先级越高,高层次的set会覆盖底层次的set,如果是层次相同再看时间先后顺序,谁发生的晚谁有效,时间靠后的会覆盖之前的。通过工厂进行覆盖有什么要求?
- 无论是重载的类(
parrot)还是被重载的类(bird),都要在定义时注册到factory机制中。
- 被重载的类(
bird)在实例化时,要使用factory机制式的实例化方式,而不能使用传统的new方式。
- 最重要的是,重载的类(
parrot)要与被重载的类(bird)有派生关系。重载的类必须派生自被重载的类,被重载的类必须是重载类的父类。
你了解uvm的factory机制和callback机制嘛
Factory机制也叫工厂机制,其存在的意义就是为了能够方便的替换TB中的实例或者已注册的类型。一般而言,在搭建完TB后,我们如果需要对TB进行更改配置或者相关的类信息,我们可以通过使用factory 机制进行覆盖,达到替换的效果,从而大大提高TB的可重用性和灵活性。要使用factory机制先要进行:- 将类注册到
factory表中
- 创建对象,使用对应的语句
(type_id::create)
- 编写相应的类对基类进行覆盖。
Callback机制其作用是提高TB的可重用性,其还可进行特殊激励的产生等,与factory类似,两者可以有机结合使用。与factory不同之处在于 callback的类还是原先的类,只是内部的callback函数变了,而factory是产生一个新的扩展类进行替换。UVM组件中内嵌callback函数或者任务
- 定义一个常见的
uvm_callbacks class
- 从
UVM callback空壳类扩展uvm_callback类
- 在验证环境中创建并登记
uvm_callback
Callback介绍一下
①callback机制作用
1)在UVM验证平台,最大用处就是为了提高验证平台的可重用性;
2)在不创建复杂的OOP层次结构前提下,针对组件中的某些行为,在其之前后之后,内置一些函数,增加或者修改UVM组件的操作,增加新的功能,从而实现一个环境多个用例;
3)还可以通过Callback机制构建异常的测试用例;
②callback机制步骤
1)在UVM组件中内嵌callback函数或任务;
2)声明一个UVM callback空壳类;
3)从UVM callback空壳类中扩展UVM callback类;
4)在验证环境中创建并登记UVM callback实例。
field_automation机制和objection机制
field_automation机制:可以自动实现copy、compare、print等三个函数。当使用uvm_field系列相关宏注册之后,可以直接调用以上三个函数,而无需自己定义。这极大的简化了验证平台的搭建,尤其是简化了driver和monitor,提高了效率。
UVM中通过objection机制来控制验证平台的关闭,需要在drop_objection之前先raise_objection。验证在进入到某一phase时,UVM会收集此phase提出的所有objection,并且实时监测所有objection是否已经被撤销了,当发现所有都已经撤销后,那么就会关闭此phase,开始进入下一个phase。当所有的phase都执行完毕后,就会调用$finish来将整个验证平台关掉。如果UVM发现此phase没有提起任何objection,那么将会直接跳转到 下一个phase中。
UVM的设计哲学就是全部由sequence来控制激励生成,因此一般情况下只在sequence中控制objection。另外还需注意的是,raise_objection语句必须在main_phase中第一个消耗仿真时间的语句之前。
UVM从哪里启动
UVM的启动 总结:
- 在导入uvm_pkg文件时,会自动创建UVM_root所例化的对象UVM_top,UVM顶层的类会提供run_test()方法充当UVM世界的核心角色,通过UVM_top调用run_test()方法.
- 在环境中输入run_test来启动UVM验证平台,run_test语句会创建一个my_case0的实例,得到正确的test_name
- 依次执行uvm_test容器中的各个component组件中的phase机制,按照顺序:
- build-phase(自顶向下构建UVM 树)
- connet_phase(自低向上连接各个组件)
- end_of_elaboration_phase
- start_of_simulation_phase
- run_phase() objection机制仿真挂起,通过start启动sequence(每个sequence都有一个body任务。当一个sequence启动后,会自动执行sequence的body任务),等到sequence发送完毕则关闭objection,结束run_phase()(UVM_objection提供component和sequence共享的计数器,当所有参与到objection机制中的组件都落下objection时,计数器counter才会清零,才满足run_phase()退出的条件)
- 执行后面的phase
phase机制以及执行顺序

注意两点:
(1)只有build phase 和final phase是自顶向下其余都是自底向上;
(2)只有run phase是任务task,其余都是function



举例说明UVM组件中常用的方法,各种phase关系,phase机制作用
UVM中有很多非常有趣的机制,例如factory机制,field_automation机制,phase机制,打印机制,sequence机制,config_db机制等,这些机制使得我们搭建的UVM能够有很好的可重用性和使得我们平台运行有秩序稳定。
- 例如
phase机制,phase机制主要是使得UVM的运行仿真层次化,使得各种例化先后次序正确。UVM的phase机制主要有9个,外加12个小phase。主要的phase有build phase、connect phase、run phase、report phase、final phase等,其中除了run phase是* task**,其余都是function,然后build phase和final phase都是自顶向下运行,其余都是自底向上运行。Run phase和12个小phase(reset phase、configure phase、main phase、shutdown phase)是并行运行的,有这12个小phase主要是进一步将run phase中的事务划分到不同的phase进行,简化代码。注意,run phase和 12个小phase最好不要同时使用。从运行上来看,9个phase顺序执行,不同组件中的同一个phase执行有顺序,build phase为自顶向下,只有同一个phase全部执行完毕才会执行下一个phase。
- 所有的
phase按照以下顺序自上而下自动执行:(九大phase,其中run phase又分为12个小phase) run_phase和main phase(动态运行)都是task phase,且是并行运行的,后者称为动态运行(run-time)的phase。- 如果想执行一些耗费时间的代码,那么要在此
phase下任意一个component中至少提起一次objection,这个结论只适用于f12个run-time的phase。对于run_phase则不适用,由于run_phase与动态运行的phase是并行运行的,如果12个动态运行的phase有objection被提起,那么run_phase根本不需要raise_objection就可以自动执行。
build_pase
connect_phase
end_of_elaboration_phase
start_of_simulation_phase
run_pase
extract_phase
check_phase
report_phase
final_phase
其中,run_phase按照以下顺序自上而下执行:
pre_reset_phase
reset_phase
post_reset_phase
pre_configure_phase
configure_phase
post_configure_phase
pre_main_phase
main_phase
post_main_phase
pre_shutdown_phase
shutdown_phase
post_shutdown_phase
phase中的domain概念
Domain是用来组织不同组件,实现独立运行的概率。默认情况下,UVM的9个phase属于 common_domain,12个小phase属于uvm_domain。例如,如果我们有两个dirver类,默认情况下,两个driver类中的复位rset_phase和 main phase必须同时执行,但是我们可以设置两个driver属于不同的domain,这样两个dirver就是独立运行的了,相当于处于不同的时钟域(只针对12个小phase有效)。run_phase和main_phase之间的关系;
main_phase要如何跳转到reset_phase;
在
main_phase执行过程中,突然遇到reset信号被置起,可以用jump()实现从mian_phase到reset_phase的跳转:接口怎么传递到环境中(通过config_db的方式)
config_db有三种方式:
- 传递virtual interface到环境中;
- 配置单一变量值,例如int、string、enum等;
- 传递配置对象(config_object)到环境;
- 传递virtual interface到环境中;
a) 虽然SV可以通过层次化的interface的索引完成传递,但是这种传递方式不利于软件环境的封装和复用。通过使用uvm_config_db配置机制来传递接口,可以将接口的传递与获取彻底分离开。
b) 接口传递从硬件世界到UVM环境可以通过uvm_config_db来实现,在实现过程中应当注意:
c) 接口传递应发生在run_test()之前。这保证了在进入build_phase之前,virtual interface已经被传递到uvm_config_db中。
d) 用户应当把interface与virtual interface区分开来,在传递过程中的类型应当为virtual interface,即实际接口的句柄。


在top层set进去,在drv中get。

2.传递配置对象(config_object)比如seq到环境; ✨
在test配置中,需要配置的参数不只是数量多,可能还分属于不同的组件。对这么多层次的变量做出类似上边的单一变量传递,需要更多的代码,容易出错且不易复用。
如果整合各个组件中的变量,将其放置在一个uvm_object中,再对中心化的配置对象进行传递,将有利于整体环境的修改维护,提升代码的复用性。



3. 配置单一变量值,例如int、string、enum等
配置单一变量值,例如int、string、enum等;在各个test中,可以在build_phase阶段对底层组件的各个变量加以配置,进而在环境例化之前完成配置,使得环境可以按照预期运行。

如何在driver中使用interface,为什么
Interface如果不进行virtual声明的话是不能直接使用在dirver中的,会报错,因为interface声明的是一个实际的物理接口。一般在dirver中使用virtual interface进行申明接口,然后通过config_db进行接口参数传递,这样我们可以从上层组件获得虚拟的interface接口进行处理。
Config_db传递时只能传递virtual接口,即interface的句柄,否则传递的是一个实际的物理接口,这在driver中是不能实现的,且这样的话不同组件中的接口一一对应一个物理接口,那么操作就没有意义了。
UVM的优势,为什么要用UVM?
UVM其实就是SV的一个封装,将我们在搭建测试平台过程中的一些重复性和重要的工作进行封装,从而使我们能够快速的搭建一个需要的测试平台,并且可重用性还高。但是UVM又不仅仅是封装。为什么复用性高,是因为,它有一个库。在这个库里,有很丰富的资源,你可以直接拿来就用。UVM作为验证方法学,在库里有很多基类,也就是父类,你如果要用,可以直接用,还可以扩展。说一下component和object的区别,item是component还是object
UVM中
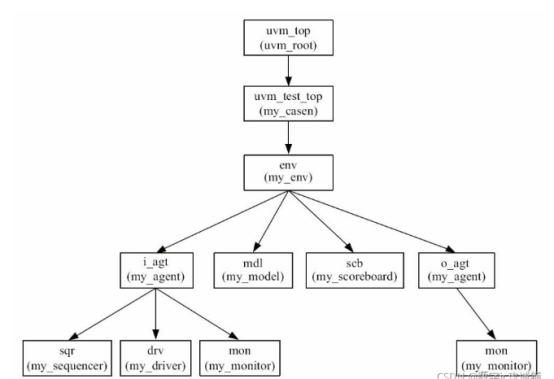
component也是由object派生出来的,不过相比于object, component有很多其没有的属性,例如phase机制和树形结构等。在UVM中,不仅仅需要component这种较为复杂的类,进行TB的层次化搭建,也需要object这种基础类进行TB的事务搭建和一些环境配置等。Item是object。UVM树形结构

大概有八个是component,分别是test,env,agent,driver,monitor,scb,sqr、model。

UVM验证环境的组成
Sequencer:负责将数据转给driver
driver负责数据的发送;driver有时钟/时序的概念。
Agent:其实只是简单的把driver,monitor和sequencer封装在一起。
Agent:对应的是物理接口协议,不同的接口协议对应不同的agent,一个平台通常会有多个agent。
Env:则相当于是一个特大的容器,将所有成员包含进去。
uvm验证环境的构成、uvm每个组件的作用、agent的作用
①uvm_sequencer
sequencer,即测序器。该组件就如同一根管道。从这个管道中会产生连续的激励事务,并最终通过TLM端口送至driver一侧。它也是一个参数类。sequencer既管理着sequence,同时也将sequence中产生的transaction item传送到driver的一侧。
② uvm_driver
driver,即驱动。该类会从uvm_sequencer类中获取事务(transaction),经过转化进而在接口(interface)中对DUT进行时序激励。任何继承于uvm_driver的类都需要注意的是:该类是参数化的类,因此在定义时需要声明参数的类型。uvm_driver类的定义如下:
class uvm_driver #(type REQ = uvm_sequence_item, type RSP = REQ) extends uvm_component;可以看出,默认的参数类型是uvm_sequence_item类的句柄,所以在声明时要注意传入子类句柄,否则会造成无法访问子类成员变量。
driver类与sequencer类之间的通信就是为了获取新的transaction,而这一操作是通过其上的TLM端口的pull的方式,从sequencer一侧get到的。
③ uvm_monitor
monitor,即监控器。该类是为了监测接口数据。任何需要用户自定义数据监测行为的monitor都应当继承于该类。
uvm_monitor组件类通常执行的功能包括:
(1)观测DUT的接口,并且收集总线信息;
(2)永远保持PASSIVE模式:即永远不会驱动DUT;
(3)在总线协议或者内部信号协议的观察时,可以做一些功能和时序的检查;
(4)对于更复杂的检查要求,它们可以将数据发送至其它验证组件,如scoreboard、reference model等。
④ uvm_agent
agent,即代理。该组件是一个容器类,是一个标准的验证环境“单元”,里面通常包含一个driver、一个monitor以及一个sequencer。
有时为了复用,uvm_agent中只需要包含一个monitor,而不需要driver和sequencer。此时可以通过设置变量 is_active 来进行有条件的例化:
uvm_active_passive_enum is_active = UVM_ACTIVE;
当is_active的值为 UVM_ACTIVE 时,表示处于active模式的agent需要例化driver、sequencer和monitor。如果值为 UVM_PASSIVE,则表示agent是passive模式,只可以例化monitor。即:active模式的agent既能激励DUT,也可以监测它;passive模式则只有监测功能。
⑤ uvm_scoreboard
scoreboard,即记分板。该组件用于进行数据的比对报告:对来自monitor的数据和来自reference_model的数据进行比对,看结果是否一致。通常会在scoreboard中声明TLM端口以供monitor传输数据。
⑥ uvm_env
env,即环境。该组件是一个结构化的容器,它可以容纳其它组件,也可以作为子环境在更高层次中被嵌入。其中例化了多个uvm_agent和其它组件,这些不同组件共同构成一个完整的验证环境。
⑦uvm_test
uvm_test为用户自定义类的顶层结构,是验证环境建立的唯一入口。只有通过uvm_test才能正常运转UVM的phase机制,进而控制整个验证平台的有序运行。它不但决定着验证环境的结构和连接关系,也决定着使用哪一个测试序列。所有的test类都应该继承于uvm_test,否则将无法启动test的运行。
Virtual sequencer 和sequencer的区别
Virtual sequencer主要用于对不同的agent进行协调时,需要有一定顶层的sequencer对内部各个agent中的sequencer进行协调
virtual sequencer是面向多个sequencer的多个sequence群,而sequencer是面向一个sequencer的sequence群。
Virtual sequencer桥接着所有底层的sequencer的句柄,其本身也不需要传递item,不需要和driver连接。只需要将其内部的底层sequencer句柄和sequencer实体对象连接。



平台往里边输入数据的话怎么输入sequence,sequence,sequencer,driver之间的通信



在多个
sequence同时向sequencer发送item时,需要有ID信息表明该item从哪个sequence来,ID信息在sequence创建item时就赋值了。Sequence和item(uvm_sequece,uvm_sequence_item)以及sequence的分类
item是基于uvm_object类,这表明了它具备UVM核心基类所必要的数据操作方法,例如copy、 clone、compare、record等。
item对象的生命应该开始于sequence的body()方法,而后经历了随机化并穿越sequencer最终到达driver,直到被driver消化之后,它的生命一般来讲才会结束。
- item与sequence的关系 一个
sequence可以包含一些有序组织起来的item实例,考虑到item在创建后需要被随机化,sequence在声明时也需要预留一些可供外部随机化的变量,这些随机变量一部分是用来通过层级传递约束来最终控制item对象的随机变量,一部分是用来对item对象之间加以组织和时序控制的。
- Sequence的分类:
- 扁平类
(flat sequence):这一类往往只用来组织更细小的粒度,即item实例构成的组织。
- 层次类
( hierarchical sequence):这一类是由更高层的sequence用来组织底层的sequence,进而让这些sequence或者按照顺序方式,或者按照并行方式,挂载到同一个sequencer上。
- 虚拟类
(virtual sequence):这一类则是最终控制整个测试场景的方式,鉴于整个环境中往往存在不同种类的sequencer和其对应的sequence,我们需要一个虚拟的sequence来协调顶层的测试场景。之所以称这个方式为virtual sequence,是因为该序列本身并不会固定挂载于某一种sequencer类型上,而是将其内部不同类型sequence最终挂载到不同的目标sequencer上面。这也是virtual sequence不同于hierarchical sequence的最大一点。
Sequence和sequencer的关系
sequence机制用于产生激励,它是UVM中最重要的机制之一。sequence机制有两大组成部分:sequence和sequencer。
- 在整个验证平台中
sequence处于一个比较特殊的位置。sequence不属于验证平台的任何一部分,但是它与sequencer之间有着密切的关系。
- 只有在
sequencer的帮助下,sequence产生的transaction才能最终送给driver;同样,sequencer只有在sequence出现的情况下才能体现出其价值,如果没有sequence,sequencer几乎没有任何作用。
- 除此之外,
sequence与sequencer还有显著的区别。从本质上说,sequencer是一个uvm_component,而sequence是一个uvm_object。与my_transaction一样,sequence也有其生命周期。它的生命周期比my_transaction要更长一点,其内部的transaction全部发送完毕后,它的生命周期也就结束了。
Sequencer的仲裁特性(set_arbitration)及锁定机制(lock和grab)
仲裁特性
锁定机制
Virtual sequence和virtual sequencer中virtual含义
Virtual含义就是其sequencer 并不需要传递item,也不会与driver连接,其只是一个去协调各个sequencer的中央路由器。通过virtual sequencer我们可以实现多个agent的多个sequencer他们的 sequence的调度和可重用。Virtual sequence可以组织不同sequencer 的sequence群落。为什么会有sequence、sequencer以及driver,为什么要分开实现,这样做的好处是什么?
- 在
UVM中有sequence机制,以往如果我们使用SV进行TB搭建时,我们一般会采用driver一个类进行数据的参数,转换,发送,或者使用genetor和driver两个进行,这种方式可重用性很低,而且代码臃肿;
- 但是在UVM中我们通过将
sequence、sequencer、driver、sequence_item拆开,相互独立而又有联系,因此我们只需关注每一个类需要做的工作就可以,可重用性高。我在学习sequence时,我经常把sequence比作蓄水池,sequence_item就是水,sequencer就是一个调度站,driver就是总工厂,通过这种方式进行处理,我们的总工厂不需要管其他,只需处理运送过来的水资源就可以,而sequencer只需要调度水资源,sequence只需要产生不同的水资源。
启动Sequence的方法
- 通过sequence.start的方式显示启动

2.通过default sequence来隐式启动也可以通过‘uvm_do系列宏启动

组件之间的通信机制,analysis port和其它的区别
- 通信分为,单向通信,双向通信和多向通信
- 单向通信:指的是从
initiator到target之间的数据流向是单一方向的
- 双向通信:双向通信的两端也分为
initiator和target,但是数据流向在端对端之间是双向的
- 多向通信:仍然是两个组件之间的通信,是指
initiator与target之间的相同TLM端口数目超过一个时的处理解决办法。
- blocking阻塞传输的方法包含:
- Put():
initiator先生成数据Tt,同时将该数据传送至target。
- Get():
initiator从target获取数据Tt,而target中的该数据Tt则应消耗。
- Peek():
initiator从target获取数据Tt,而target中的该数据Tt还应保留。
- 通信管道:
TLM FIFO:可以进行数据缓存,功能类似于mailbox,不同的地方在于uvm_tlm_fifo提供了各种端口(put、get、peek)供用户使用
analysis port:一端对多端,用于多个组件同时对一个数据进行处理,如果这个数据是从同一个源的TLM端口发出到达不同组件,则要求该端口能够满足一端到多端,如果数据源端发生变化需要通知跟它关联的多个组件时,我们可以利用软件的设计模式之一观察者模式实现,即广播模式
analysis TLM FIFO
a. 由于
analysis端口提出实现了一端到多端的TLM数据传输,而一个新的数据缓存组件类uvm_tlm_analysis_fifo为用户们提供了可以搭配uvm_analysis_port端口uvm_analysis_imp端口和write()函数。b.
uvm_tlm_analysis_fifo类继承于uvm_tlm_fifo,这表明它本身具有面向单一TLM端口的数据缓存特性,而同时该类又有一个uvm_analysis_imp端口analysis_export并且实现了write()函数:- request & response通信管道 双向通信端口
transport,即通过在target端实现transport()方法可以在一次传输中既发送request又可以接收response。
UVM各个component之间的通信机、UVM TILM通信,解释一下
①通信分为,单向通信,双向通信和多向通信
· 单向通信:指的是从initiator到target之间的数据流向是单一方向的
· 双向通信:双向通信的两端也分为initiator和target,但是数据流向在端对端之间是双向的
· 多向通信:仍然是两个组件之间的通信,是指initiator与target之间的相同TLM端口数目超过一个时的处理解决办法。
· 通信端口按照类型可以划分为三种:
1)port:通信请求方initiator的发起端,initiator凭借port端口才可以访问target。
2)export:作为initiator和target中间层次的端口。
3)imp:只能作为target接收请求的响应端,它无法作为中间层次的端口,所以imp的连接无法再次延伸。
②blocking阻塞传输的方法包含:
· Put():initiator先生成数据Tt,同时将该数据传送至target。
· Get():initiator从target获取数据Tt,而target中的该数据Tt则应消耗。
· Peek(): initiator从target获取数据Tt,而target中的该数据Tt还应保留。
③通信管道:
· TLM FIFO:可以进行数据缓存,功能类似于mailbox,不同的地方在于uvm_tlm_fifo提供了各种端口(put、get、peek)供用户使用
· analysis port:一端对多端,用于多个组件同时对一个数据进行处理,如果这个数据是从同一个源的TLM端口发出到达不同组件,则要求该端口能够满足一端到多端,如果数据源端发生变化需要通知跟它关联的多个组件时,我们可以利用软件的设计模式之一观察者模式实现,即广播模式
· analysis TLM FIFO
1)由于analysis端口提出实现了一端到多端的TLM数据传输,而一个新的数据缓存组件类uvm_tlm_analysis_fifo为用户们提供了可以搭配uvm_analysis_port端口uvm_analysis_imp端口和write()函数。
2)uvm_tlm_analysis_fifo类继承于uvm_tlm_fifo,这表明它本身具有面向单一TLM端口的数据缓存特性,而同时该类又有一个uvm_analysis_imp端口analysis_export并且实现了write()函数:
· request & response通信管道 双向通信端口transport,即通过在target端实现transport()方法可以在一次传输中既发送request又可以接收response。
TLM怎么用
TLM通信的步骤:
- 分辨出
initiator和target,producer和consumer。
- 在
target中实现tlm通信方法。
- 在俩个对象中创建
tlm端口。
- 在更高层次中将俩个对象进行连接。
- 端口类型有三种:
port,一般是initiator的发起端。
export,作为initiator和target的中间端口。
imp,只能作为target接受request的末端。
- 多个
port可以连接同一个export或imp,但是单个port或export不能连接多个imp。
- 端口的连接:通过
connect函数进行连接,例如A(initiator)与B进行连接,可以使用A.port.connect(B.export)
- uvm_*_imp#(T,IMP);IMP定义中第一个参数T是这个IMP传输的数据类型,第二个参数IMP是实现这个接口所在的
component。
UVM组件的通信方式TLM的接口分类和用法,peek和get的差异
UVM中采用事务级传输机制进行组件间的通信,可以大大提高仿真的速度和使得我们简化组件间的数据传输,简化工作,TLM独立于组件之外,降低组件间的依赖关系。UVM接口主要由port、export、imp;驱动这些接口方式有put、get、peek、transport、analysis等。
- 其中
peek是查看端口内部的数据事务但是不删除,get是获取后立即删除。我们一般会先使用peek进行获取数据,但不删除(保证put端不会立马又发送一个数据),处理完毕后再用get删除。
- lmp只能作为终点接口,transport表示双向通信,analysis可以连接多个imp(类似于广播)。
Analysis port是否可以不连或者连多个impport
都可以。
Analysis port类似于广播,其可以同时对多个imp进行事务通信,只需要在每一个对应的imp端口申明write()函数即可。对比 put,get,peek port,他们都只能进行一对一传输,且也必须申明对应的函数如 put()、get()、peek()、can_put()/do_put()等。Fifo是可以不用申明操作函数的,其内部封装了很多的通信端口,如analysis_export等,我们只需要将端口与其连接即可实现通信。你所搭建的验证平台为什么要用RAL(寄存器)
- 首先,我们要了解寄存器对于设计的重要性,其是模块间交互的窗口,我们可以通过读寄存器值去观察模块的运行状态,通过写寄存器去控制模块的配置和功能改变。
- 然后,为什么我们需要RAL呢?由于前面寄存器的重要性,我们可以知道,如果我们不能先保证我们寄存器的读写正确,那么就不用谈后续 DUT是否正确了,因此,寄存器的验证是排在首要位置的。
- 那么我们应该用什么方法去读写和验证寄存器呢?采用RAL寄存器模型去测试验证,是目前最成功的方法吧,寄存器模型独立于
TB之外,我们可以搭建一个测试寄存器的agent,去通过前门或者后门访问去控制DUT的寄存器,使得DUT按照我们的要求去运行。
- 除此之外,
UVM中内建了很多RAL的sequence,用于帮助我们去检测寄存器,除此之外,还有一些其他的类和变量去帮助我们搭建,以提高RAL的可重用性和便捷性还有更全的覆盖率。
前门访问和后门访问的区别
- 前门访问和后门访问的比较
- 前门访问,顾名思义指的是在寄存器模型上做的读写操作,最终会通过总线UVC来实现总线上的物理时序访问,因此是真实的物理操作。
- 后门访问,指的是利用
UVM DPI (uvm_hdl_read()、uvm_hdl_deposit()),将寄存器的操作直接作用到DUT内的寄存器变量,而不通过物理总线访问。
- 前门访问在使用时需要将
path设置为UVM_FRONTDOOR
- 在进行后门访问时,用户首先需要确保寄存器模型在建立时,是否将各个寄存器映射到了
DUT一侧的HDL路径:使用add_hdl_path
5. 从上面的差别可以看出,后门访问较前门访问更便捷更快一些,但如果单纯依赖后门访问也不能称之为“正道”。6. 实际上,利用寄存器模型的前门访问和后门访问混合方式,对寄存器验证的完备性更有帮助。
后门访问的路径怎么配置
如果寄存器的地址不匹配的错误怎么测试出来
在通过前门配置寄存器A之后,再通过后门访问来判断HDL地址映射的寄存器A变量值是否改变,最后通过前门访问来读取寄存器A的值。
寄存器模型的常规方法(期望值、镜像值、真实值)
mirror、desired、actual value()- 我们在应用寄存器模型的时候,除了利用它的寄存器信息,也会利用它来跟踪寄存器的值。寄存器有很多域,每一个域都有两个值。
- 寄存器模型中的每一个寄存器,都应该有两个值,一个是镜像值(
mirrored value) , 一个是期望值(desired value) 。
- 期望值是先利用寄存器模型修改软件对象值,而后利用该值更新硬件值;镜像值是表示当前硬件的已知状态值。
- 镜像值往往由模型预测给出,即在前门访问时通过观察总线或者在后门访问时通过自动预测等方式来给出镜像值
- 镜像值有可能与硬件实际值不一致
寄存器模型里,update()和mirror()方法的作用
①mirror()不会返回读回的值,但是会将对应的镜像值修改。在修改镜像值之前,用户还可以选择是否将读回的值与模型中的原镜像值进行比较;
②当寄存器的期望值与镜像值不相同时,可以通过update()方法来将不相同的寄存器通过前门访问或者后门访问的方式做全部修改
Prediction的分类(自动预测和显式预测)
- UVM提供了两种用来跟踪寄存器值的方式,我们将其分为自动预测(
auto prediction)和显式预测(explicit)。
- 如果用户想使用自动预测的方式,还需要调用函数
uvm_reg_map::set_auto predict()
- 两种预测方式的显著差别在于,显式预测对寄存器数值预测更为准确,我们可以通过下面对两种模式的分析得出具体原因。自动预测
- 如果用户没有在环境中集成独立的
predictor,而是利用寄存器的操作来自动记录每一次寄存器的读写数值,并在后台自动调用predict()方法的话,这种方式被称之为自动预测。
- 这种方式简单有效,然而需要注意,如果出现了其它一些
sequence直接在总线层面上对寄存器进行操作(跳过寄存器级别的write/read操作,或者通过其它总线来访问寄存器等这些额外的情况,都无法自动得到寄存器的镜像值和预期值。显式预测
- 更为可靠的一种方式是在物理总线上通过监视器来捕捉总线事务,并将捕捉到的事务传递给外部例化的
predictor,该predictor由UVM参数化类uvm_reg_predictor例化并集成在顶层环境中。
- 在集成的过程中需要将
adapter与map的句柄也一并传递给predictor,同时将monitor采集的事务通过analysis port接入到predictor一侧。
- 这种集成关系可以使得,
monitor一旦捕捉到有效事务,会发送给predictor,再由其利用adapter的桥接方法,实现事务信息转换,并将转化后的寄存器模型有关信息更新到map中。
- 默认情况下,系统将采用显式预测的方式,这就要求集成到环境中的总线
UVC monitor需要具备捕捉事务的功能和对应的analysis port,以便于同predictor连接。
寄存器怎么配置,adapter怎么集成
对UVM验证方法学的理解
- 刚开始接触的时候,我认为
UVM其实就是SV的一个封装,将我们在搭建测试平台过程中的一些重复性和重要的工作进行封装,从而使我们能够快速的搭建一个需要的测试平台,并且可重用性还高。因此我当时觉得它就是一个库。
- 不过,随着学习的不断深入,当我深入理解
UVM中各种机制和模型的构造和相互之间关系之后,我觉得其实UVM方法学对于使用何种语言其实并不重要,重要的是他的思想,比如:在UVM中有sequence机制,以往如果我们使用SV进行TB搭建时,我们一般会采用driver一个类进行数据的产生,转换,发送,或者使用generator和driver两个进行,这种方式可重用性很低,而且代码臃肿;但是在UVM中我们通过将sequence、sequencer、driver、sequence_item拆开,相互独立而又有联系,因此我们只需关注每一个类需要做的工作就可以,可重用性高。我在学习sequence时,我经常把sequence比作蓄水池,sequence_item就是水,sequencer就是一个调度站,driver就是总工厂,通过这种方式进行处理,我们的总工厂不需要管其他,只需处理运送过来的水资源就可以,而sequencer只需要调度水资源,sequence只需要产生不同的水资源。而这种处理方式和现实世界中的生产模式又是基本吻合的。除此之外,还有好多好多,其实UVM方法学中很多思想就是来源于经验,来源于现实生活,而不在乎是何种语言。
UVM有什么优缺点:
- UVM的优点:UVM有各个机制、促进验证平台的标准化,UVM中
test sequence和验证平台是隔离独立的,可以更好的控制激励而不需要重新设计agent. 改变测试sequence可以简单高效提高代码覆盖率。UVM支持工业标准,这会促进验证平台标准化。此外,UVM通过OOP(面向对象编程)的特点(例如继承)以及使用覆盖组件提高了重复使用率。因此UVM环境方便移植,架构清晰,组件连接方便,有利于进行大规模的验证。
- UVM的缺点:代码冗余,工作量大,运行速度有缺失
请谈一下UVM的验证环境结构,各个组件间的关系
画出
UVM的验证环境结构,如图所示首先,
UVM测试平台基本是由object和 component组成的,其中 component搭建了TB的一个树形结构,其基本包含了driver、monitor、sequencer、agent、scoreboard、model、env、test、top;然后object一般包含sequence_item、config和一些其他需要的类。各个组件相互独立,又通过TLM事务级传输进行通信,除此之外,DUT 与driver和 monitor 又通过interface进行连接,实现驱动和采集,最后在top层进行例化调用test进行测试。其他问题
IC设计流程也即ASIC设计流程
芯片架构-RTL设计-功能仿真-综合&扫描链的插入(DFT)-等价性检查-形式验证-静态时序分析(STA)-布局规划-布局布线-布线图和原理图比较-设计规则检查-GDII


代码覆盖率、功能覆盖率和断言覆盖率的区别
- 代码覆盖率——是针对RTL设计代码的运行完备度的体现,包括行覆盖率、条件覆盖率、FSM覆盖率、跳转覆盖率、分支覆盖率,只要仿真就可以收集,可以看DUT的哪部分代码没有动,如果有一部分代码一直没动看一下是不是case没有写到。
- 功能覆盖率---与
spec比较来发现,design是否行为正确,需要按verification plan来比较进度。用来衡量哪些设计特征已经被测试程序测试过的一个指标
- 首要的选择是使用更多的种子来运行现有的测试程序;
- 其次是建立新的约束,只有在确实需要的时候才会求助于定向测试,改进功能覆盖率最简单的方法是仅仅增加仿真时间或者尝试新的随机种子。
- 验证的目的就是确保设计在实际环境中的行为正确。设计规范里详细说明了设备应该如何运行,而验证计划里则列出了相应的功能应该如何激励、验证和测量
- 断言覆盖率:用于检查几个信号之间的关系,常用在查找错误,主要是检查时序上的错误,测量断言被触发的频繁程度。
项目中会考虑哪些coverage
- 主要会考虑三个方面吧,代码覆盖率,功能覆盖率,断言覆盖率。
- 代码覆盖率,主要由行覆盖率、条件覆盖率、
fsm覆盖率、跳转覆盖率、分支覆盖率,他们是否都是运行到的,比如fsm,是否各个状态都运行到了,然后不同状态之间的跳转是否也都运行到了。
- 功能覆盖率的话主要是自己编写
covergroup和coverpoint去覆盖我们想要覆盖的数据和地址或者其他控制信号。
- 断言覆盖率主要检测我们的时序关系是否都运行到了,比如总线的地址数据读写时序关系是否都有实现。
Coverage一般不会直接达到100%,当你发现condition未cover到的时候,你该怎么做?
Condition又称为条件覆盖率,当条件覆盖率未被覆盖时,我们需要通过查看覆盖率报告去定位哪些条件没有被覆盖到,是因为没有满足该条件的前提条件还是因为根本就遗漏了这些情况,根据这个我们去编写相应的case,进而将其覆盖到。covergroup在哪里定义,哪里例化,有哪些,分别怎么做采样,根据什么来写
Function coverage和 Code coverage的区别,以及他们分别对项目的含义
- 功能覆盖率主要是针对
spec文档中功能点的覆盖检测 -code覆盖率主要是针对RTL设计代码的运行完备度的体现,其包括行覆盖率、条件覆盖率、FSM覆盖率、跳转覆盖率、分支覆盖率(只要仿真就可以,看看DUT的哪些代码没有动,如果有一部分代码一直没动,看一下是不是case没写到)。
- 功能覆盖率和代码覆盖率两者缺一不可,功能覆盖率表示着代设计是否具备这些功能,代码覆盖率表示我们的测试是否完备,代码是否冗余。当功能覆盖率高而代码覆盖率低时,表示
covergroup是不是写少了,case写少了;或者代码冗余。当功能覆盖率很低而代码覆盖率高时,表示代码设计是不是全面,功能点遗漏;covergroup写的是不是冗余了。只有当两者覆盖率都高的时候才表明我们验证的大部分是可靠的。
- 代码覆盖率很难达到100%,一般情况下达到90%多已经非常不错了,如果有一部分代码没有被触动到,需要有经验的验证工程师去分析,如果确实没啥问题,就可以签字通过了
你在做验证时的流程是怎么样的,你是怎么做的。
对于流程的话
- 首先第一步我会先去查看
spec文档,将模块的功能和接口总线时序搞明白,尤其是工作的时序,这对于后续写TB非常重要;
- 第二步我会根据功能点去划分我的
TB应该怎么搭建,我的case大致会有哪些,这些功能点我应该如何去覆盖,时序应该如何去检查,总结列出这样的一个清单;
- 第三步开始去搭建我们的
TB,包括各种组件,和一些基础的sequence还有test,暂时先就写一两个基础的sequence,然后还有一些环境配置参数的确定等,最后能够将TB正常运行,保证无误;
- 第四步就是根据清单去编写
sequence和case,然后去仿真,保证仿真正确性,收集覆盖率;
- 第五步就是分析收集的覆盖率,然后查看覆盖率报告去分析还有哪些没有被覆盖,去写一些定向
case,和更换不同的seed去仿真;
- 第六步就是回归测试
regression,通过不同的seed去跑,收集覆盖率和检测是否有其它bug;
- 第七步就是总结
你在进行验证的过程中,碰到过什么难点,重点是什么呢?
- 刚开始的难点还是TB的搭建,想要搭建出一个可重用性很高的TB,配置灵活的TB还是有一定困难,对于哪些参数应该放在配置类,哪些参数应该放在事务类的抉择,哪些单独配置。
- 除此之外,还有就是时序的理解,这对于
driver和monitor还有sequence和assertion的编写至关重要,只有正确理解时序才能编写出正确的TB。
- 最后就是实现覆盖率的尽可能高,这也是比较困难的,刚开始的
case好写,也比较快就可以达到较高的覆盖率,但是那些边边角角的case需要自己去琢磨,去分析还需要写什么case。这些难点就是重点,还要能够自动化监测判断是否正确。
定向测试和随机测试的区别,为什么现在越来越多的随机测试?
优点:对于较大规模的设计,随机测试相比定向测试可以产生更完备的测试向量,测试的覆盖范围更大,能够找出预料不到的漏洞。
缺点:随机测试的环境复杂度更高,带来了更高的封装要求,同时建立随机测试环境周期也更长。

形式验证
- 形式验证指从数学上完备地证明或验证电路的实现方案是否确实实现了电路设计所描述的功能。形式验证方法分为等价性验证、模型检验和定理证明等。
- 形式验证主要验证数字IC设计流程中的各个阶段的代码功能是否一致,包括综合前RTL代码和综合后网表的验证,因为如今IC设计的规模越来越大,如果对门级网表进行动态仿真,会花费较长的时间,而形式验证只用几个小时即可完成一个大型的验证。另外,因为版图后做了时钟树综合,时钟树的插入意味着进入布图工具的原来的网表已经被修改了,所以有必要验证与原来的网表是逻辑等价的
如何保证验证的完备性?
- 首先不可能百分百完全完备,即遍历所有信号的组合,这既不经济也不现实。
- 所以只能通过多种验证方法一起验证尽可能减少潜在风险,一般有这些验证流程:ip级验证、子系统级验证、soc级验证,除这些以外,还有upf验证、fpga原型验证等多种手段。
- 前端每走完一个阶段都需要跟设计以及系统一起
review验证功能点,测试用例,以及特殊情况下的波形等。
- 芯片后端也会做一些检查,像sta、formality、DFM、DRC检查等,也会插入一些DFT逻辑供流片回来测试用。流片归来进行测试,有些bug可以软件规避,有些不能规避,只能重新投片
触发器和锁存器的区别
- 触发器:时钟触发,受时钟控制,只有在时钟触发时才采样当前的输入,产生输出。
- 锁存器由电平触发,非同步控制。在使能信号有效时锁存器相当于通路,在使能信号无效时锁存器保持输出状态。触发器由时钟沿触发,同步控制。
- 锁存器对输入电平敏感,受布线延迟影响较大,很难保证输出没有毛刺产生;触发器则不易产生毛刺
怎么编写测试用例?
主要是编写
sequence,然后在body里面根据测试功能要求写相应的激励,然后再通过ref_model和checker判断功能是否实现?验证流程,验证环境怎么搭
- 验证流程:
- 看
spec文档和协议,将DUT的功能和接口总线时序搞明白
- 制定验证计划和测试点分解
- 写
VIP或者是用别人给的VIP,搭建验证环境和TB,包括各种组件,各个模块的pkg,基础的sequence还有test,暂时先就写一两个基础的sequence,然后还有一些环境配置参数的确定等,最后能够将TB正常运行,保证无误;
- 根据测试点编写
sequence和case,然后去仿真,保证仿真正确性,收集覆盖率;
- 分析收集的覆盖率,然后查看覆盖率报告去分析还有哪些没有被覆盖,去写一些定向
case,和更换不同的seed去仿真;
- 回归测试
regression,通过不同的seed去跑,收集覆盖率和检测是否有其它bug;
- 总结
- 验证环境的搭建:
driver给 DUT 发送激励,montior监测 DUT 输出的数据,参考模型( reference model )能实现与 DUT相同的功能,scoreboard把 monitor接受到的数据和 reference model的输出数据进行比对,如果比对成功就表示 DUT 能完成设计的功能,AMBA总线中AHB/APB/AXI协议的区别
AHB(Advanced High-performance Bus)高级高性能总线。APB(Advanced Peripheral Bus)高级外围总线AXI (Advanced eXtensible Interface)高级可拓展接口AHB主要是针对高效率、高频宽及快速系统模块所设计的总线,它可以连接如微处理器、芯片上或芯片外的内存模块和DMA等高效率模块。
APB主要用在低速且低功率的外围,可针对外围设备作功率消耗及复杂接口的最佳化。APB在AHB和低带宽的外围设备之间提供了通信的桥梁,所以APB是AHB的二级拓展总线。
AXI高速度、高带宽,管道化互联,单向通道,只需要首地址,读写并行,支持乱序,支持非对齐操作,有效支持初始延迟较高的外设,连线非常多。
AHB协议
1. AHB的组成
Master:能够发起读写操作,提供地址和控制信号,同一时间只有1个Master会被激活。
Slave:在给定的地址范围内对读写操作作响应,并对Master返回成功、失败或者等待状态。
Arbiter:负责保证总线上一次只有1个Master在工作。仲裁协议是规定的,但是仲裁算法可以根据应用决定。
Decoder:负责对地址进行解码,并提供片选信号到各Slave。每个AHB都需要1个仲裁器和1个中央解码器。
2. AHB基本信号(经常会问Htrans和Hburst,以及AHB的边界地址怎么确定)
- HADDR:32位系统地址总线。
- HTRANS:M指示传输状态,NONSEQ、SEQ、IDLE、BUSY。
- HWRITE:传输方向1-写,0-读。
- HSIZE:传输单位。
- HBURST:传输的burst类型,SINGLE、INCR、WRAP4、INCR4等。
- HWDATA:写数据总线,从M写到S。
- HREADY:S应答M是否读写操作传输完成,1-传输完成,0-需延长传输周期。
- HRESP:S应答当前传输状态,OKAY、ERROR、RETRY、SPLIT。
- HRDATA:读数据总线,从S读到M。
APB协议及读写操作
1. APB的状态转移
2. APB写操作
3. APB读操作
a[*3]、a[->3]和a[=3]区别
- a[*3]指的是:重复3次a,且其与前后其他序列不能有间隔,a中间也不可有间隔。
- a[->3]指的是:重复3次,其 a中间可以有间隔,但是其后面的序列与a之间不可以有间隔。
- a[=3]指的是:只要重复3次,中间可随意间隔。
你发现过哪些验证过程中的 bug,如何发现的,怎么解决的?
这个问题面试的时候经常问,建议面试之前考虑一下,再做决定
你的验证环境是什么?目录结构是什么样的
我是使用
UVM验证方法学搭建的TB,然后在VCS平台进行仿真的。目录结构的话:主要由RTL文件、doc文件、tb文件、sim文件、script文件这几部分。ASIC芯片设计流程
规格制定-详细设计- HDL编码-仿真验证-逻辑综合- STA-形式验证。具体为
1、规格制定
芯片规格,也就像功能列表一样,是客户向芯片设计公司提出的设计要求,包括芯片需要达到的具体功能和性能方面的要求。
2、详细设计
Fabless根据客户提出的规格要求,拿出设计解决方案和具体实现架构,划分模块功能。
3、HDL编码
使用硬件描述语言VHDL,将模块功能以代码来描述实现,也就是将实际的硬件电路功能通过HDL语言描述出来,形成RTL代码。
4、仿真验证
仿真验证就是检验编码设计的正确性,检验的标准就是第一步制定的规格。看设计是否精确地满足了规格中的所有要求。规设计和仿真验证是反复迭代的过程,直到验证结果显示完全符合规格标准。仿真验证工具Mentor公司的Modelsim, Synopsys的VCS,还有Cadence的Veridi均可以对RTL级的代码进行设计验证。
5、逻辑综合――Design Compiler
仿真验证通过,进行逻辑综合。逻辑综合的结果就是把设计实现的HDL代码翻译成门级网表netlist。综合需要设定约束条件,就是你希望综合出来的电路在面积,时序等目标参数上达到的标准。逻辑综合需要基于特定的综合库,不同的库中,门电路基本标准单元(standard cell)的面积,时序参数是不一样的。所以,选用的综合库不一样,综合出来的电路在时序,面积上是有差异的。一般来说,综合完成后需要再次做仿真验证(这个也称为后仿真,之前的称为前仿真)逻辑综合工具Synopsys的Design Compiler,仿真工具选择上面的三种仿真工具均可。
6、STA
静态时序分析,这也属于验证范畴,它主要是在时序上对电路进行验证,检查电路是否存在建立时间(setup time)和保持时间(hold time)的违例(violation)。这个是数字电路基础知识,一个寄存器出现这两个时序违例时,是没有办法正确采样数据和输出数据的,所以以寄存器为基础的数字芯片功能肯定会出现问题。STA工具有Synopsys的Prime Time。
7、形式验证
这也是验证范畴,它是从功能上对综合后的网表进行验证。常用的就是等价性检查方法,以功能验证后的HDL设计为参考,对比综合后的网表功能,他们是否在功能上存在等价性。这样做是为了保证在逻辑综合过程中没有改变原先HDL描述的电路功能。形式验证工具有Synopsys的Formality。从设计程度上来讲,前端设计的结果就是得到了芯片的门级网表电路。
iC设计前端到后端的流程和EDA工具?
设计前端也称逻辑设计,后端设计也称物理设计,两者并没有严格的界限,一般涉及到与工艺有关的设计就是后端设计。
1:规格制定:客户向芯片设计公司提出设计要求;
2:详细设计:芯片设计公司(Fabless)根据客户提出的规格要求,拿出设计解决方案和具体实现架构,划分模块功能。目前架构的验证一般基于systemC语言,对价后模型的仿真可以使用systemC的仿真工具。例如:CoCentric和Visual Elite等;
3:HDL编码:设计输入工具:ultra,visualVHDL等;
4:仿真验证:modelsim;
5:逻辑综合:synplify
6:静态时序分析:synopsys的PrimeTime
7、形式验证:Synopsys的Formality
参考资料






const (ref)、input、output、inout分别是什么意思?
input端口是输入端口;output是输出端口;
inout端口用于双向连接。如果使用多个inout端口驱动一个信号,sv将会根据所有驱动器的值,驱动强度来计算最终的值。
在sysytemverilog中,通过ref参数的传递方式指定为引用而不是复制,不需要创建数据包副本消耗内存。这种ref函数类型比input,output和inout更好用,首先你可以把数组传递给子程序;
ref端口是对变量(不能是net)的引用,它的值是该变量最后一次赋的值。如果将一个变量链接到多个ref端口,就可能产生竞争,因为多个模块的端口都可能更新同一个变量。
使用ref和const传递数组,如下:

const修饰符,虽然数组变量a指向了调用程序中的数组,但是子程序不能修改数组的值,如果你试图改变数组的值,编译器将报错。
systemverilog允许不带ref进行数组的传递,这时数组会被复制到堆栈区中,这种操作的代价很高,除非是对特别小的数组。
systemverilog的语言参考手册规定了ref参数只能用于带自动存储的子程序中(automatic funtion/automatic task/void function)。如果你对程序或模块指定了automatic属性,则整个程序内部都是自动存储的。
全局变量和局部变量的作用域是什么,静态变量和动态变量的区别是什么?
全局变量具有全局作用域。全局变量只需在一个源文件中定义,就可以作用于所有的源文件。当然,其他不包含全局变量定义的源文件需要用extern 关键字再次声明这个全局变量。
静态局部变量具有局部作用域,它只被初始化一次,自从第一次被初始化直到程序运行结束都一直存在,它和全局变量的区别在于全局变量对所有的函数都是可见的,而静态局部变量只对定义自己的函数体始终可见。
局部变量也只有局部作用域,它是自动对象(auto),它在程序运行期间不是一直存在,而是只在函数执行期间存在,函数的一次调用执行结束后,变量被撤销,其所占用的内存也被收回。
静态全局变量也具有全局作用域,它与全局变量的区别在于如果程序包含多个文件的话,它作用于定义它的文件里,不能作用到其它文件里,即被static关键字修饰过的变量具有文件作用域。这样即使两个不同的源文件都定义了相同名字的静态全局变量,它们也是不同的变量。
动态变量::int i;
静态变量:static int i;
动态变量在子程序中,每次调用都会从它的初始值开始调用,而不管他在函数中经历了什么变化;静态变量会从变化后的值继续改变。
总结:
- static全局变量与普通的全局变量有什么区别:static全局变量只初使化一次,防止在其他文件单元中被引用。
- static局部变量和普通局部变量有什么区别:static局部变量只被初始化一次,下一次依据上一次结果值。
- static函数与普通函数有什么区别:static函数在内存中只有一份,普通函数在每个被调用中维持一份拷贝。
- 全局变量和静态变量如果没有手工初始化,则由编译器初始化为0。局部变量的值不可知。
package的作用使用,使用package和include有什么区别?
sv中的package与c++中的namespace类似,都是为了解决命名冲突的问题。不同package里面的内容是可以重名的。使用时加pkg_name::xxx来指定用哪个pkg_name里面的xxx。
include是编译预处理语句,是将文件中的内容插入到当前文件中。
import是package里面的全部identifiers 或者指定identifiers 对当前作用域可见。
什么是OOP,三大要素是什么,三大要素在SV中分别使用什么来实现的,使用OOP有什么好处,SV中有重载吗,覆盖和重载的区别是什么
①重载是指不同的函数使用相同的函数名,但是函数的参数个数或类型不同。调用的时候根据函数的参数来区别不同的函数。
②覆盖(也叫重写)是指在派生类中重新对基类中的虚函数(注意是虚函数)重新实现。即函数名和参数都一样,只是函数的实现体不一样
SV的覆盖率如何声明,如何采集覆盖率,bin的数量如何确定,交叉覆盖率的作用是什么,ignore和illegal的bin如果触发了有什么区别
SV的仿真调度机制是什么样的?
UVM的历史,从哪些项目中分别获得了什么特性?
UVM的优势和劣势是什么,一定要使用UVM吗?
UVM如何启动测试?如何把接口传递到环境中
config_db机制的作用是什么,如何使用,set以后一定要get吗?什么情况下可以不get?
什么是域的自动化机制,域的自动化机制提供了哪些特性
sequence机制是什么,为什么要设计sequence,什么是layer sequence、 virtual sequence?
什么是phase机制,phase有哪些,什么条件下可以进入下一个phase,各个phase的作用是什么,各个phase的执行顺序是怎么样的?
UVM的消息是如何管理的,冗余度的意义是什么
一个典型的UVM环境纯在哪些组件,数据是如何流动的,每个组件的作用是什么
component和object有什么共同点和区别
什么是事务级建模,TLM接口的作用,如何使用TLM接口,TLM FIFO的作用是什么
有哪些验证手段?动态仿真、形式验证都有什么优缺点
门级仿真的作用是什么,STA的作用是什么
给一个模块,要能够根据SPEC进行功能点的分解,提出覆盖率
功能覆盖率和代码覆盖率什么意思,这些覆盖率不够怎么办,覆盖率满了就能说验证完备吗
- 作者:Conor
- 链接:https://www.xzhh.top/article/interview
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。