
type
status
date
slug
summary
tags
category
Property
Jul 8, 2023 02:47 PM
icon
password
属性
属性 1
描述
Origin
URL
设计第一个游戏变量和字符串开始代码游戏改进数值类型布尔类型短路逻辑和运算符优先级流程图和思维导图分支与循环分支结构的嵌套循环continueelse嵌套for 循环列表1.1 创建列表1.2 访问列表中的元素1.3 下标索引1.4 列表切片2.1 增(向列表添加数据)2.2 删(删除列表中的数据)2.3 改2.4 查3.1 列表的加法和乘法3.2 嵌套列表3.3 访问嵌套列表3.4 通过 for 语句来创建并初始化二维列表3.5 深拷贝和浅拷贝4.1 列表推导式4.2 列表的高级用法4.3 带条件筛选功能的列表推导式元组字符串1.1 引入:利用字符串方法轻松解决回文数问题1.2 字符串方法讲解:大小写字母换来换去1.3字符串方法讲解:左中右对齐2.1字符串方法讲解:查找2.2 字符串方法讲解:替换3.1 字符串方法讲解:判断4.1. 字符串方法讲解:截取4.2 字符串方法讲解:拆分4.3 字符串方法讲解:拼接5.1 格式化字符串5.2 字符串格式化语法参考6.1 字符串格式化语法参考6.2 更灵活的玩法6.3 f-字符串序列1.1 列表、元组、字符串的共同点1.2 加号(+)和乘号(*)1.3. 关于 “可变” 和 “不可变” 的思考1.4.是(is)和不是(is not)1.5 包含(in)和不包含(not in)1.6 del 语句2.1 list()、tuple() 和 str()2.2 min() 和 max()2.3 len() 和 sum()3.1 all() 和 any()3.2 enumerate()3.3 zip()3.4 map()3.5. filter()与map()3.6 可迭代对象和迭代器字典1.1引子1.2 映射关系1.3 使用列表实现莫斯密码解密1.4 使用字典实现莫斯密码解密2.1.字典的关键特征2.2 创建字典2.3 增2.4删3.1 改3.2 查3.3 视图对象3.4我们可以对字典做些什么?3.5 嵌套3.6 字典推导式集合函数1.函数Ⅰ2.函数Ⅱ3.函数Ⅲ函数Ⅳ函数Ⅴ函数Ⅵ-装饰器函数Ⅶ数(VIII)- 生成器函数IX- 递归函数(X)- 汉诺塔参考资料资料下载
设计第一个游戏
注意事项:标点英文;缩进正确;函数名正确。
内置函数查询命令
变量和字符串
交换变量
字符串
开始代码
游戏改进
1.要有提示,猜的数字是大是小,使用if,else语句
2.要有三次机会,猜中,使用while循环,打断循环使用了break
3.使用随机数,import导入random模块
random 其实调用的是当前计算机的时间作为种子,然后进行计算;
只要将当前状态赋值给x,再重新random发现数值一样
数值类型
浮点数
计算机会自带位数,所以小数直接相加是不会等于算数上的小数的,只有导入decimal模块后才会正常计数;
复数可以用.real和.imag调用实部和虚部;
输入太多位的小数会用科学计数法表示。
运算符 | 描述 |
[] [:] | 下标,切片 |
** | 指数 |
~ + - | 按位取反, 正负号 |
* / % // | 乘,除,模,整除 |
+ - | 加,减 |
>> << | 右移,左移 |
& | 按位与 |
^ | | 按位异或,按位或 |
<= < > >= | 小于等于,小于,大于,大于等于 |
== != | 等于,不等于 |
is is not | 身份运算符 |
in not in | 成员运算符 |
not or and | 逻辑运算符 |
= += -= *= /= %= //= **= &= ` | = ^= >>= <<=` |

int():将一个数值或字符串转换成整数,可以指定进制。
float():将一个字符串转换成浮点数。
str():将指定的对象转换成字符串形式,可以指定编码。
chr():将整数转换成该编码对应的字符串(一个字符)。
ord():将字符串(一个字符)转换成对应的编码(整数)。
布尔类型
定义为False的对象包括:
1.None和False
2.值为0的数字类型:0,0.0,0j,Decimal(0),Fraction(0,1)
3.空的序列和集合:”,(),[],{},set(),range(0)
几乎在任何一个编程语言中最重要的是分支语句和循环语句,条件那就是真真假假的布尔运算的结果
True和False就是两个特殊的整数代表1和0。
逻辑运算符
and or not
任何对象都能直接进行真值测试(测试该对象的布尔类型值为True或者False)
and 左右都为真则取右边
or 左边为真就取左边
短路逻辑和运算符优先级
短路逻辑:从左至右,只有当第一个操作数的值无法确定逻辑运算的结果时,才对第二个操作数进行求值。
运算符优先级
数字越大级别越高
优先级 | 运算符 | 描述 |
1 | lambda | Lambda 表达式 |
2 | if - else | 条件表达式 |
3 | or | 布尔“或” |
4 | and | 布尔“与” |
5 | not x | 布尔“非” |
6 | in, not in, is, is not, <, <=,>, >=, !=, == | 成员测试,同一性测试,比较 |
7 | | | 按位或 |
8 | ^ | 按位异或 |
9 | & | 按位与 |
10 | <<, >> | 移位 |
11 | +, - | 加法,减法 |
12 | *, @, /, //, % | 乘法,矩阵乘法,除法,地板除,取余数 |
13 | +x,-x, ~x | 正号,负号,按位非(翻转) |
14 | ** | 指数 |
15 | await x | Await 表达式 |
16 | x[index], x[index:index], x(arguments...), x.attribute | 下标,切片,函数调用,属性引用 |
17 | (expressions...), [expressions...], {key: value...}, {expressions...} | 绑定或元组显示,列表显示,字典显示,集合显示 |

流程图和思维导图
流程图




思维导图



分支与循环
分支结构
第 1 种是判断一个条件,如果这个条件成立,就执行其包含的某条语句或某个代码块。
语法结构如下:
第 2 种同样是判断一个条件,跟第 1 种的区别是如果条件不成立,则执行另外的某条语句或某个代码块。
第 3 种是判断多个条件,如果第 1 个条件不成立,则继续判断第 2 个条件,如果第 2 个条件还不成立,则接着判断第 3 个条件……
如果还有第 4、5、6、7、8、9 个条件,你还可以继续写下去。
第 4 种是在第 3 种的情况下添加一个 else,表示上面所有的条件均不成立的情况下,执行某条语句或某个代码块。

如果分支结构非常复杂选择左边的结构,否则右边。
分支结构的嵌套
可以一直嵌套,但是要注意代码的颜值,非常重要!
循环
1. 循环结构
能跟分支大佬平起平坐的也就是循环结构了,分支结构能让你的程序根据条件去做不同的事情,而循环机构能让你的程序去不断做同一件事情,这就是所谓的道不同而一样很牛逼啦!
Python 有两种循环语句:while 循环和 for 循环。
2.while循环
只要条件一直成立,那么其包含的某条语句或某个代码块就会一直被执行。
3. 死循环
如果条件一直成立,那么循环体就一直被执行。
按下ctrl+c终止
4. break 语句
在循环体内,一旦遇到 break 语句,Python 二话不说马上就会跳出循环体,即便这时候循环体内还有待执行的语句。

continue
实现跳出循环体还有另外一个语句,那就是 continue 语句。
continue 语句也会跳出循环体,但是,它只是跳出本一轮循环,它还会回到循环体的条件判断位置,然后继续下一轮循环(如果条件还满足的话)。
注意它和 break 语句两者的区别:
- continue 语句是跳出本次循环,回到循环的开头
- break 语句则是直接跳出循环体,继续执行后面的语句
else
当循环的条件不再为真的时候,便执行 else 语句的内容。
while-else 可以非常容易地检测到循环的退出情况。
编辑模式
交互模式
嵌套
循环也能玩嵌套,而且玩得更六!
有时候,我们的需求可能要用到不止一层循环来实现。
比如我们要实现打印一个九九乘法表,就可以这么实现:
嵌套循环,内层循环完了才会让上一层循环,内层打印八次,外层7次
当内层出现break时,只会终结该层循环并跳出该层循环,不会影响上层循环,因此,出现七次结果。
如果是全部打断的话,只会打印一次。
下面的代码都是执行的外层循环打印七次,到break就打断了。

for 循环
什么是可迭代对象?
所谓可迭代对象,就是指那些元素能够被单独提取出来的对象。比如我们学过的字符串,它就是一个可迭代对象。
什么叫迭代呢?
比如说让你每一次从字符串 "FishC" 里面拿一个字符出来,那么你依次会拿出 'F'、'i'、's'、'h'、'C' 五个字符,这个过程我们称之为迭代。
想用for循环从1加到1000,但是发现1000数字不可迭代。
和for一起的好兄弟一般是range,
range() 会帮你生成一个数字序列,它的用法有以下三种:
- range(stop) - 将生成一个从 0 开始,到 stop(不包含)的整数数列
- range(start, stop) - 将生成一个从 start 开始,到 stop(不包含)的整数数列
- range(start, stop, step) - 将生成一个从 start 开始,到 stop(不包含)结束,步进跨度为 step 的整数数列
注意:无论你使用哪一种,它的参数都只能是整数。
实现1加到1000。注意range的范围不包含
寻找素数
注意使用//地板除可以得到整数。
for 循环和 while 循环的共通性
for 循环和 while 循环一样,都是可以支持嵌套的,同样它也可以搭配 break 和 continue 语句。

列表
1.1 创建列表
创建一个列表非常简单,我们只需要使用中括号,将所有准备放入列表中的元素给包裹起来,不同元素之间使用逗号分隔:
1.2 访问列表中的元素
如果希望按顺序访问列表的每一个元素,可以使用 for 循环语句:
如果希望随机访问其中一个元素,那么可以使用下标索引的方法:
1.3 下标索引
序列类型的数据都可以使用下标索引的方法,第一个元素的下标是 0,第二个的下标是 1,以此类推:

Python 还支持你 “倒着” 进行索引:

1.4 列表切片
将原先的单个索引值改成一个范围即可实现切片:
2.1 增(向列表添加数据)
向列表添加元素可以使用 append() 方法,它的功能是在列表的末尾添加一个指定的元素。
append() 方法虽好,不过每次它只能添加一个元素到列表中,而 extend() 方法则允许一次性添加多个元素:
注意:extend() 方法的参数必须是一个可迭代对象,然后新的内容是追加到原列表最后一个元素的后面。
使用万能的切片语法,也可以实现列表元素的添加:
insert() 方法允许你在列表的任意位置添加数据。
insert() 方法有两个参数,第一个参数指定的是插入的位置,第二个参数指定的是插入的元素:
2.2 删(删除列表中的数据)
利用 remove() 方法,可以将列表中指定的元素删除:
这里有两点要注意的:
- 如果列表中存在多个匹配的元素,那么它只会删除第一个
- remove() 方法要求你指定一个待删除的元素,如果指定的元素压根儿不存在,那么程序就会报错
有时候我们可能需要删除某个指定位置上的元素,那么可以使用 pop() 方法,它的参数就是元素的下标索引值:
pop() 方法这个参数其实是可选的,如果你没有指定一个参数,那么它“弹”出来的就是最后一个元素:
如果想要一步到位清空列表,可以使用 clear() 方法:

2.3 改
列表跟字符串最大区别就是:列表是可变的,而字符串是不可变的。
替换列表中的元素跟访问元素类似,都是使用下标索引的方法,然后使用赋值运算符就可以将新的值给替换进去了:
如果有连续的多个元素需要替换,可以利用切片来实现:
排序与翻转
sort() 方法还可以实现排序后翻转(即从大到小的排序):
2.4 查
如果我们想知道 nums 这个列表里面到底有多少个 3,可以使用 count() 方法:
如果我们要查找 heros 列表中,"绿巨人"这个元素的索引值,可以使用 index() 方法:
index() 方法有两个可选的参数 —— start 和 end,就是指定查找的开始和结束的下标位置:
列表还有一个方法叫 copy(),用于拷贝一个列表:
我们也可以使用切片的语法来实现列表拷贝:
上面这两种拷贝方法实现的效果是等同的。这两种拷贝的方法,在 Python 中都称为浅拷贝。

3.1 列表的加法和乘法
列表的加法,其实也是拼接,所以要求加号(+)两边都应该是列表,举个例子:
列表的乘法,则是重复列表内部的所有元素若干次:
3.2 嵌套列表
Python 是允许列表进行嵌套的:
可以把创建二维列表的语句这么写:
3.3 访问嵌套列表
访问嵌套列表中的元素,可以使用嵌套的 for 语句来实现:
通过下标同样可以访问嵌套列表:
3.4 通过 for 语句来创建并初始化二维列表
注意事项
高级错误B,虽然也能创建列表但是存储在同一空间中,复制的是引用


3.5 深拷贝和浅拷贝
变量不是盒子
在一些编程语言中,经常会有 “变量就是盒子” 这样的比喻,因为赋值操作就像是往盒子里面放东西。
但在 Python 中变量并不是一个盒子,当赋值运算发生的时候,Python 并不是将数据放进变量里面,而是将变量与数据进行挂钩,这个行为我们称之为引用。
浅拷贝:利用列表的 copy() 方法或者切片来实现
深拷贝:利用 copy 模块的 deepcopy() 函数来实现
浅拷贝可以用于处理一维列表,对于嵌套列表的拷贝,只能拷贝第一层数据,其余仅拷贝其引用:

深拷贝可以用于处理多维列表:


4.1 列表推导式
掌握好列表推导式,会使你的代码变得更为简练和高效。
比如下面这个循环语句:
注意:这可不仅仅是少写了一行代码而已,从程序的执行效率上来说,列表推导式的效率通常是要比循环语句快上一倍左右的速度。
基础语法
列表推导式的基本语法如下:
处理矩阵
利用列表推导式处理矩阵也是非常方便,比如下面代码是将矩阵第 2 列的元素给提取出来:
又比如,下面代码是获取矩阵主对角线上的元素(就是从左上角到右下角这条对角线上的元素):

重申创建二维列表的错误方法
不要这样去创建二维列表:
因为如果你试图修改其中的一个元素,就会发现有多个元素同时被修改了:
这是因为内部嵌套的列表不是三个独立的列表,而是同一个列表的三次引用而已。
所以,正确的做法应该是:
更好的方法
利用列表推导式,就可以很轻松地创建一个二维列表:
4.2 列表的高级用法
4.3 带条件筛选功能的列表推导式
列表推导式其实还可以添加一个用于筛选的 if 分句,完整语法如下:
每层嵌套还可以附带一个用于条件筛选的 if 分句:
KISS 原则,重要!
程序设计开发中有一个非常重要原则:KISS。
KISS 原则的全称是 Keep It Simple and Stupid,也就是 “Python之禅” 里面提到的 “简洁胜于复杂”。
编程不是为了炫耀聪明和晦涩,而是为了让你的代码可以清楚地表达它们的目的。
尽管列表推导式可以使得代码非常简洁,执行效率也比传统的循环语句要快得多得多。
不过,如果由于使用了过分复杂的列表推导式,从而导致后期的阅读和维护代码的成本变得很高,那么就得不偿失了。

元组
元组既能像列表那样同时容纳多种类型的对象,也拥有字符串不可变的特性。
元组和列表的不同点
- 列表是使用方括号,元组则是圆括号(也可以不带圆括号)
- 列表中的元素可以被修改,而元组不行
- 列表中涉及到修改元素的方法元组均不支持
- 列表的推导式叫列表推导式,元组的 “推导式” 叫生成器表达式
元组和列表的共同点
- 都可以通过下标获取元素
- 都支持切片操作
- 都支持 count() 方法和 index() 方法
- 都支持拼接(+)和重复(*)运算符
- 都支持嵌套
- 都支持迭代
圆括号的必要性
小甲鱼个人的建议是:与其纠结什么时候省略圆括号不会带来问题,还不如一直都加上为妙!
况且,这样做也有助于增加代码的可读性。
当元组只有一个元素的时候
不要这么写:
要这么写:
打包和解包
生成一个元组我们有时候也称之为元组的打包:
将它们一次性赋值给三个变量名的行为,我们称之为解包:
需要注意的一点是:赋值号左侧的变量名数量,必须跟右侧序列的元素数量一致,否则通常都会报错。
吃瓜:多重赋值的真相
相当于:
元组真的就固若金汤了吗?
那倒未必:
元组中的元素虽然是不可变的,但如果元组中的元素是指向一个可变的列表,那么我们依然是可以修改列表中的内容的。

字符串
1.1 引入:利用字符串方法轻松解决回文数问题
1.2 字符串方法讲解:大小写字母换来换去
capitalize()、casefold()、title()、swapcase()、upper()、lower()
1.3字符串方法讲解:左中右对齐
center(width, fillchar=' ')、ljust(width, fillchar=' ')、rjust(width, fillchar=' ')、zfill(width)

2.1字符串方法讲解:查找
2.2 字符串方法讲解:替换
xpandtabs([tabsize=8])、replace(old, new, count=-1)、translate(table)
首先是expandtabs([tabsize=8])方法,它的作用是使用空格替换制表符并返回新的字符串。比如你现在在路边捡到一段代码,里面混了着 Tab 和空格:
那么使用 expandtabs(tabsize=4)
方法,就可以将字符串中的 Tab 转换成空格,其中 tabsize 参数指定的是一个 Tab 使用多少个空格来代替:
replace(old, new, count=-1)
方法返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串。另外,还有一个 count 参数是指定替换的次数,默认值 -1 表示替换全部。
translate(table)
方法,这个是返回一个根据 table 参数(用于指定一个转换规则的表格)转换后的新字符串。
需要使用
str.maketrans(x[, y[, z]])
方法制定一个包含转换规则的表格。
这个 str.maketrans()
方法还支持第三个参数,表示将其指定的字符串忽略:

3.1 字符串方法讲解:判断
startswith(prefix[, start[, end]])、endswith(suffix[, start[, end]])、istitle()、isupper()、islower()、isalpha()、isascii()、isspace()、isprintable()、isdecimal()、isdigit()、isnumeric()、isalnum()、isidentifier()
这 14 个方法都是应对各种情况的判断,所以返回的都是一个布尔类型的值 —— 要么是 True,要么是 False。
startswith(prefix[, start[, end]]) 方法用于判断 prefix 参数指定的子字符串是否出现在字符串的起始位置:
对应的,endswith(suffix[, start[, end]]) 方法则相反,用于判断 suffix 参数指定的子字符串是否出现在字符串的结束位置:
这两个方法都有 start 和 end 两个可选的参数,用于指定匹配的开始和结束位置:
很多童鞋最后还是喜欢看小甲鱼的课程,可能就是因为很多教材不会告诉你的东西,小甲鱼会告诉你。
嘿嘿,这个 prefix 和 suffix 参数呀,其实是支持以元组的形式传入多个待匹配的字符串的:
如果你希望判断一个字符串中的所有单词是否都是以大写字母开头,其余字母均为小写,那么可以使用 istitle() 方法进行测试:
如果你希望判断一个字符串中所有字母是否都是大写,可以使用 isupper() 方法进行测试:
相反,判断是否所有字母都是小写,用 islower() 方法,我们这里就不再赘述了。
如果你希望判断一个字符串中是否只是由字母组成,可以使用 isalpha() 方法进行检测:
如果你希望判断一个字符串中是否只是由 ASCII 字符组成,可以使用 isascii() 方法进行检测:
如果你希望判断是否为一个空白字符串,可以用 isspace() 方法进行检测:
如果你希望判断一个字符串中是否所有字符都是可打印的,可以使用 isprintable() 方法:
isdecimal()、isdigit() 和 isnumeric() 三个方法都是用来判断数字的。
首先是十进制数字:
如果写成罗马数字:
或者中文数字:
isdecimal() 和 isdigit() 方法都败下阵来了,但 isnumeric() 方法,其实连繁体数字也难不倒它地:
isalnum() 方法则是集大成者,只要 isalpha()、isdecimal()、isdigit() 或者 isnumeric() 任意一个方法返回 True,结果都为 True。
最后,isidentifier() 方法用于判断该字符串是否一个合法的 Python 标识符
就是如果你想判断一个字符串是否为 Python 的保留标识符,就是像 “if”、“for”、“while” 这些关键字的话,可以使用 keyword 模块的 iskeyword() 函数来实现:

4.1. 字符串方法讲解:截取
lstrip(chars=None)、rstrip(chars=None)、strip(chars=None)、removeprefix(prefix)、removesuffix(suffix)
这几个方法都是用来截取字符串的:
这三个方法都有一个chars=None的参数,None 在 Python 中表示没有,意思就是去除的是空白。
那么这个参数其实是可以给它传入一个字符串的:
如果只是希望踢掉一个具体的子字符串,应该怎么办?
那么你可以考虑 removeprefix(prefix) 和 removesuffix(suffix) 这两个方法。
它们允许你指定将要删除的前缀或后缀:
4.2 字符串方法讲解:拆分
partition(sep)、rpartition(sep)、split(sep=None, maxsplit=-1)、rsplit(sep=None, maxsplit=-1)、splitlines(keepends=False)
拆分字符串,言下之意就是把字符串给大卸八块,比如 partition(sep) 和 rpartition(sep) 方法,就是将字符串以
sep
参数指定的分隔符为依据进行切割,返回的结果是一个 3 元组(3 个元素的元组):
partition(sep) 和 rpartition(sep) 方法的区别是前者是从左往右找分隔符,后者是从右往左找分隔符:
注意:它俩如果找不到分隔符,返回的仍然是一个 3 元组,只不过将原字符串放在第一个元素,其它两个元素为空字符串。
split(sep=None, maxsplit=-1) 和 rsplit(sep=None, maxsplit=-1) 方法则是可以将字符串切成一块块:
splitlines(keepends=False) 方法会将字符串进行按行分割,并将结果以列表的形式返回:
keepends
参数用于指定结果是否包含换行符,True 是包含,默认 False 则表示是不包含:
4.3 字符串方法讲解:拼接
join(iterable) 方法是用于实现字符串拼接的。
虽然的它的用法在初学者看来是非常难受的,但是在实际开发中,它却常常是受到大神追捧的一个方法。
字符串是作为分隔符使用,然后
iterable
参数指定插入的子字符串:


5.1 格式化字符串
在字符串中,格式化字符串的套路就是使用一对花括号({})来表示替换字段,就在原字符串中先占一个坑的意思,然后真正的内容被放在了
format()方法的参数中。比如:
在花括号里面,可以写上数字,表示参数的位置:
注意,同一个索引值是可以被多次引用的:
还可以通过关键字进行索引,比如:
当然,位置索引和关键字索引可以组合使用:
如果我只是想单纯的输出一个纯洁的花括号,那应该怎么办呢?
有两种办法可以把这个纯洁的花括号安排进去:
5.2 字符串格式化语法参考
以下所解锁的新知识,可以直接在字符串的format()方法上使用,也可以用于 Python3.6 后新添加的f-字符串。
5.2.1 对齐选项

5.2.2 填充选项([fill])
在指定宽度的前面还可以添加一个 '0',则表示为数字类型启用感知正负号的 '0' 填充效果:
注意,如果是非数字字符串,新版会把0放后面,旧版报错。
还可以在对齐([align])选项的前面通过填充选项([fill])来指定填充的字符:

6.1 字符串格式化语法参考
6.1.1 符号([sign])选项
符号([sign])选项仅对数字类型有效,可以使用下面3个值:

6.1.2 精度([.precision])选项
精度([.precision])选项是一个十进制整数,对于不同类型的参数,它的效果是不一样的:
- 对于以 'f' 或 'F' 格式化的浮点数值来说,是限定小数点后显示多少个数位
- 对于以 'g' 或 'G' 格式化的浮点数值来说,是限定小数点前后共显示多少个数位
- 对于非数字类型来说,限定最大字段的大小(换句话说就是要使用多少个来自字段内容的字符)
- 对于整数来说,则不允许使用该选项值
6.1.3 类型([type])选项
类型([type])选项决定了数据应该如何呈现。
以下类型适用于整数:
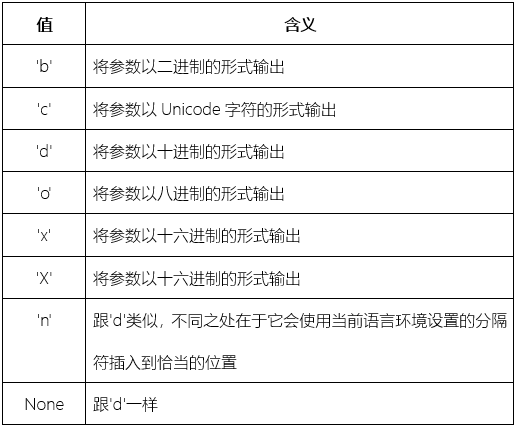
以下类型值适用于浮点数、复数和整数(自动转换为等值的浮点数)如下:
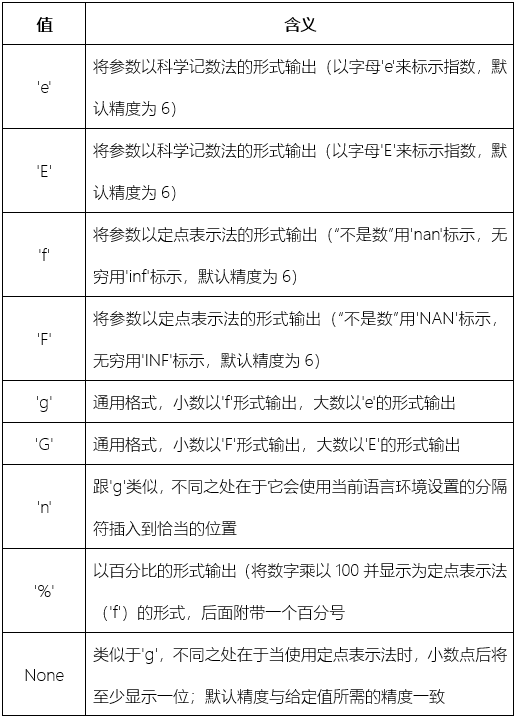
6.2 更灵活的玩法
Python 事实上支持通过关键参数来设置选项的值,比如下面代码通过参数来调整输出的精度:
同时设置多个选项也是没问题的,只要你自己不乱,Python 就不会乱:
6.3 f-字符串
Python 随着版本的更迭,它的语法也是在不断完善的。“简洁胜于复杂”是 Python 之禅中强调的理念。
因此,在Python3.6的更新中,他们给添加了一个新的语法,叫 f-string,也就是 f-字符串。f-string 可以直接看作是format()方法的语法糖,它进一步简化了格式化字符串的操作并带来了性能上的提升。
注:语法糖(英语:Syntactic sugar)是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。

序列
1.1 列表、元组、字符串的共同点
- 都可以通过索引获取每一个元素
- 第一个元素的索引值都是 0
- 都可以通过切片的方法获得一个范围内的元素的集合
- 有很多共同的运算符
因此,列表、元组和字符串,Python 将它们统称为序列。
根据是否能被修改这一特性,可以将序列分为可变序列和不可变序列:比如列表就是可变序列,而元组和字符串则是不可变序列。
1.2 加号(+)和乘号(*)
首先是加减乘除,只有加号(+)和乘号(*)可以用上,序列之间的加法表示将两个序列进行拼接;乘法表示将序列进行重复,也就是拷贝:
1.3. 关于 “可变” 和 “不可变” 的思考
可变序列:
不可变序列:
虽然可变序列和不可变序列看上去都是 “可变” 的,但实现原理却是天壤之别:可变序列是在原位置修改 “扩容”,而不可变序列则是将内容 “扩容” 后再放到一个新的位置上去。
1.4.是(is)和不是(is not)
是(is)和不是(is not)被称之为同一性运算符,用于检测两个对象之间的 id 值是否相等:
1.5 包含(in)和不包含(not in)
in 运算符是用于判断某个元素是否包含在序列中的,而 not in 则恰恰相反:
1.6 del 语句
del 语句用于删除一个或多个指定的对象:

2.1 list()、tuple() 和 str()
这三个 BIF 函数主要是实现列表、元组和字符串的转换。
2.2 min() 和 max()
这两个函数的功能是:对比传入的参数,并返回最小值和最大值。
它们都有两种函数原型:
这第一种传入的是一个可迭代对象:
这第二种传入多个参数,它们会自动找出其中的最小值和最大值:
2.3 len() 和 sum()
len()函数我们前面用过好多次了,基本用法不必啰嗦,大家都懂~
不过它有个最大的可承受范围,可能有些同学还不知道,比如说这样:
这个错误是由于 len() 函数的参数太大导致的,我们知道 Python 为了执行的效率,它内部几乎都是用效率更高的 C 语言来实现的。
而这个 len() 函数为了让 Python 自带的数据结构可以走后门,它会直接读取 C 语言结构体里面对象的长度。所以,如果检测的对象超过某个数值,就会出错。
通常对于 32 位平台来说,这个最大的数值是 2**31 - 1;而对于 64 位平台来说,这个最大的数值是 2**63 - 1。sum()函数用于计算迭代对象中各项的和:
它有一个 start参数,用于指定求和计算的起始数值,比如这里我们设置为从 100 开始加起:
2.4 sorted() 和 reversed()
sorted()函数将重新排序iterable参数中的元素,并将结果返回一个新的列表:
sorted() 函数也支持 key和 reverse两个参数,用法跟列表的 sort() 方法一致:
sorted(t, key=len) 这个,因为这个key参数,指定的是一个干预排序算法的函数。比如这里我们指定为 len() 函数,那么 Python 在排序的过程中,就会先将列表中的每一个元素调用一次 len() 函数,然后比较的是 len() 返回的结果。所以,sorted(t, key=len) 比较的就是每个元素的长度。reversed()函数将返回参数的反向迭代器。
举个例子:
大家看,它不是直接返回所见即所得的结果,它返回的一串奇奇怪怪的英文……
刚刚我们说过,它返回的结果是一个迭代器,并且我们可以把它当可迭代对象处理。
既然如此,我们就可以使用 list() 函数将其转换为列表:

3.1 all() 和 any()
all()函数是判断可迭代对象中是否所有元素的值都为真;
any()函数则是判断可迭代对象中是否存在某个元素的值为真。
3.2 enumerate()
enumerate()函数用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从 0 开始的序号共同构成一个二元组的列表:
它有一个 start参数,可以自定义序号开始的值:
3.3 zip()
zip()函数用于创建一个聚合多个可迭代对象的迭代器。做法是将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第 i 个元组包含来自每个参数的第 i 个元素。
注意,就是如果传入的可迭代对象长度不一致,那么将会以最短的那个为准:
当我们不关心较长的可迭代对象多出的数据时,使用zip()函数无疑是最佳的选择,因为它自动裁掉多余的部分。但是,如果那些值对于我们来说是有意义的,我们可以使用itertools模块的zip_longest()函数来代替:
3.4 map()
map()函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器:
3.5. filter()与map()
函数类似,filter()函数也是需要传入一个函数作为参数,不过filter()
函数是根据提供的函数,对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回:
3.6 可迭代对象和迭代器
最大的区别是:可迭代对象咱们可以对其进行重复的操作,而迭代器则是一次性的!
将可迭代对象转换为迭代器:iter()函数。

字典
1.1引子
“字典这个数据结构活跃在所有Python程序的背后,即便你的源码里并没有直接用到它。”—— A.M.Kuchling
这是收录在《代码之美》里面的一段话,字典之所以如此优秀,是因为它是Python中唯一实现了映射关系的内置类型。
1.2 映射关系
莫斯密码表就是利用映射关系来生成的:

这里的字母A和.-就是其中的一对映射关系,字母U和..-又是另一对映射关系,那么有了这张表,破解莫斯密码就不再是什么难题了。
1.3 使用列表实现莫斯密码解密
使用两个列表表示映射:
1.4 使用字典实现莫斯密码解密

2.1.字典的关键特征
字典是 Python 中唯一实现映射关系的内置类型。
字典的关键符号是大括号({})和冒号(:)
2.2 创建字典
2.3 增
首先是 fromkeys (iterable[, value])方法,这个可以算是字典中最特殊的方法,它可以使用 iterable 参数指定的可迭代对象来创建一个新字典,并将所有的值初始化为value参数指定的值:
2.4删
删除字典中的指定元素我们可以使用pop()方法:

3.1 改
类似于序列的操作,只需要指定一个存在于字典中的键,就可以修改其对应的值:
3.2 查
最简单的查方法就是你给它一个键,它返回你对应的值:
3.3 视图对象
items()、keys()和values()三个方法分别用于获取字典的键值对、键和值三者的视图对象。
什么是视图对象呢?
字面上的解释是:视图对象就是字典的一个动态视图,这意味着当字典内容改变时,视图对象的内容也会相应地跟着改变。
3.4我们可以对字典做些什么?
比如,使用len()函数来获取字典的键值对数量:
3.5 嵌套
字典也是可以嵌套的,某个键的值是另外一个字典,并不是什么稀奇的事儿。
3.6 字典推导式

集合
1. 创建集合
创建一个集合通常有三种方法:
- 使用花括号,元素之间以逗号分隔:
{"FishC", "Python"}
- 使用集合推导式:
{s for s in "FishC"}
- 使用类型构造器,也就是 set():
set("FishC")
2. 集合具有随机性
从这里不难发现,集合无序的特征,传进去的是'F'、'i'、's'、'h'、'C',它这里显示的却是 'i'、'C'、's'、'F'、'h',在你们的电脑上结果还可能不一样,这就是随机性。
由于集合是无序的,所以我们不能使用下标索引的方式去访问它:
不过可以使用 in和 not in来判断某个元素是否存在于集合中:
3. 访问集合
如果想要访问集合中的元素,可以使用迭代的方式:
4. 集合必杀技 —— 去重
集合另外一个特点就是唯一性,这也是集合最大的优势。比如利用集合,就可以轻松地实现去重的操作:
在实际开发中,我们经常需要去检测一个列表中是否存在相同的元素?
那么在没有学习过集合之前,我们很有可能需要通过迭代来统计每个元素出现的次数,从而判断是否唯一……
5. 集合的方法
集合的各种方法大合集 ->
列表、元组、字符串、字典它们都有一个
copy()方法,那么集合也不例外:
如果我们要检测两个集合之间是否毫不相干,可以使用 isdisjoint(other)
方法:
那么这个参数它并不要求必须是集合类型,可以是任何一种可迭代对象:
下面也是一样的,传入的参数,都只要求是可迭代对象的类型即可。
如果我们要检测该集合是否为另一个集合的子集,可以使用
issubset(other)方法:

6. 冻结的集合
Python 将集合细分为可变和不可变两种对象,前者是set(),后者是frozenset():
7. 仅适用于 set() 对象的方法
update(*others)方法使用others容器中的元素来更新集合:
8. 可哈希
想要正确地创建字典和集合,是有一个刚性需求的 —— 那就是字典的键,还有集合的元素,它们都必须是可哈希的。
如果一个对象是可哈希的,那么就要求它的哈希值必须在其整个程序的生命周期中都保持不变。通过hash()函数,可以轻松获取一个对象的哈希值:
9. 嵌套的集合
如果要实现一个嵌套的集合,可不可行?

函数
1.函数Ⅰ
1.1函数的作用
Python 函数的主要作用就是打包代码。
有两个显著的好处:
- 可以最大程度地实现代码重用,减少冗余的代码
- 可以将不同功能的代码段进行封装、分解,从而降低结构的复杂度,提高代码的可读性
1.2创建和调用函数
我们使用 def 语句来定义函数,紧跟着的是函数的名字,后面带一对小括号,冒号下面就是函数体,函数体是一个代码块,也就是每次调用函数时将被执行的内容:
1.3 函数的参数
从调用角度来看,参数可以细分为:形式参数(parameter)和实际参数(argument)。
其中,形式参数是函数定义的时候写的参数名字(比如下面例子中的
name和times);实际参数是在调用函数的时候传递进去的值(比如下面例子中的"Python"和5)。
1.4函数的返回值
有时候,我们可能需要函数干完活之后能给一个反馈,这在 BIF 函数中也很常见,比如sum()函数会返回求和后的结果,len()函数会返回一个元素的长度,而list()函数则会将参数转换为列表后返回……只需要使return语句,就可以让咱们自己定制的函数实现返回:

2.函数Ⅱ
2.1 位置参数
在通常的情况下,实参是按照形参定义的顺序进行传递的:
由于在定义函数的时候,就已经把参数的名字和位置确定了下来,我们将 Python 中这类位置固定的参数称之为位置参数。
2.2 关键字参数
使用关键字参数,我们只需要知道形参的名字就可以:
尽管使用关键字参数需要你多敲一些字符,但对于参数特别多的函数,这一招尤其管用。
如果同时使用位置参数和关键字参数,那么使用顺序是需要注意一下的:
比如这样就不行了,因为位置参数必须是在关键字参数之前,之间也不行哈。
2.3 默认参数
Python 还允许函数的参数在定义的时候指定默认值,这样以来,在函数调用的时候,如果没有传入实参,那么将采用默认的参数值代替:
4. 只能使用位置参数
在使用help()函数查看函数文档的时候呢,经常会在函数原型的参数中发现一个斜杠(/),比如:
2.5 只能使用关键字参数
既然有限制 “只能使用位置参数”,那有没有那种限制 “只能使用关键字参数” 的语法呢?那就是利用星号(*):

3.函数Ⅲ
3.1收集参数
什么叫收集参数呢?
当我们在定义一个函数的时候,假如需要传入的参数的个数是不确定的,按照一般的写法可能需要定义很多个相同的函数然后指定不同的参数个数,这显然是很麻烦的,不能根本解决问题。
为解决这个问题,Python 就推出了收集参数的概念。所谓的收集参数,就是说只指定一个参数,然后允许调用函数时传入任意数量的参数。
定义收集参数其实也很简单,即使在形参的前面加上星号(*)来表示:
3.2 解包参数
这一个星号(*)和两个星号(**)不仅可以用在函数定义的时候,在函数调用的时候也有特殊效果,在形参上使用称之为参数的打包,在实参上的使用,则起到了相反的效果,即解包参数:

函数Ⅳ
4.1 局部作用域
如果一个变量定义的位置是在一个函数里面,那么它的作用域就仅限于函数中,我们将它称为局部变量。
4.2 全局作用域
如果是在任何函数的外部去定义一个变量,那么它的作用域就是全局的,我们也将其称为全局变量:
4.3 global 语句
通常我们无法在函数内部修改全局变量的值,除非使用global语句破除限制:
4.4 嵌套函数
函数也是可以嵌套的:
4.5 nonlocal 语句
通常我们无法在嵌套函数的内部修改外部函数变量的值,除非使用nonlocal语句破除限制:
4.6 LEGB 规则
只要记住LEGB,那么就相当于掌握了 Python 变量的解析机制。
其中:
- L 是 Local,是局部作用域
- E 是 Enclosed,是嵌套函数的外层函数作用域
- G 是Global ,是全局作用域
- B 是 Build-In,也就是内置作用域
最后一个是B,也就是 Build-In,最没地位的那一个。
比如说 Build-In Function —— BIF,你只要起一个变量名跟它一样,那么就足以把这个内置函数给 “毁了”:
是不是,它本来的功能是将参数转换成字符串类型,但由于我们将它作为变量名赋值了,那么 Python 就把它给覆盖了:

函数Ⅴ
5.1 嵌套作用域的特性
对于嵌套函数来说,外层函数的作用域是会通过某种形式保存下来的,它并不会跟局部作用域那样,调用完就消失。
5.2 闭包
所谓闭包(closure),也有人称之为工厂函数(factory function)。
举个例子:
这里 power() 函数就像是一个工厂,由于参数不同,得到了两个不同的 “生产线”,一个是 square(),一个是 cube(),前者是返回参数的平方,后者是返回参数的立方。
5.3 闭包应用举例
比如说在游戏开发中,我们需要将游戏中角色的移动位置保护起来,不希望被其他函数轻易就能够修改,所以我们就可以利用闭包:

函数Ⅵ-装饰器
6.1 装饰器
装饰器本质上也是一个函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外的功能。
使用了装饰器,我们并不需要修改原来的代码,只需要在函数的上方加上一个@time_master,然后函数就能够实现统计运行时间的功能了。
这个 @ 加上装饰器名字其实是个语法糖,装饰器原本的样子应该这么调用的:
- f-string 里面谈到过语法糖,我们说语法糖是某种特殊的语法,对语言的功能没有影响,但对程序员来说,有更好的易用性,简洁性、可读性和方便性。
多个装饰器也可以用在同一个函数上:
这样的话,就是先计算平方(square装饰器),再计算立方(cube装饰器),最后再加 1(add装饰器)。
如何给装饰器传递参数呢?答案是添加多一层嵌套函数来传递参数:
我们将语法糖去掉,拆解成原来的样子,你就知道原理了:
这里其实就是给它裹多一层嵌套函数上去,然后通过最外层的这个函数来传递装饰器的参数。
这样,logger(msg="A")得到的是timemaster()函数的引用,然后再调用一次,并传入funA,也就是这个logger(msg="A")(funA),得到的就是call_func()函数的引用,最后将它赋值回funA()。
咱们对比一下没有参数的猫述器,这里其实就是添加了一次调用,然后通过这次调用将参数给传递进去而已。
函数Ⅶ
7.1 lambda 表达式
lambda 表达式,也就是大牛们津津乐道的匿名函数。
只要掌握了 lambda 表达式,你也就掌握了一行流代码的核心 —— 仅使用一行代码,就能解决一件看起来相当复杂的事情。
它的语法是这样的:
lambda 是个关键字,然后是冒号,冒号左边是传入函数的参数,冒号后边是函数实现表达式以及返回值。
我们可以将 lambda 表达式的语法理解为一个极致精简之后的函数,如果使用传统的函数定义方式,应该是这样:
如果要求我们编写一个函数,让它求出传入参数的平方值,以前我们这么写:
现在我们这么写:
传统定义的函数,函数名就是一个函数的引用:
而 lambda 表达式,整个表达式就是一个函数的引用:
7.2 lambda 表达式的优势
lambda 是一个表达式,因此它可以用在常规函数不可能存在的地方:
注意:这里说的是将整个函数的定义过程都放到列表中哦~
7.3 与 map() 和 filter() 函数搭配使用
4. 总结
lambda 是一个表达式,而非语句,所以它能够出现在 Python 语法不允许 def 语句出现的地方,这是它的最大优势。
但由于所有的功能代码都局限在一个表达式中实现,因此,lambda 通常只能实现那些较为简单的需求。
当然,Python 肯定是有意这么设计的,让 lambda 去做那些简单的事情,我们就不用花心思去考虑这个函数叫什么,那个函数叫什么……
def 语句则负责用于定义功能复杂的函数,去处理那些复杂的工作。

数(VIII)- 生成器
8.1 生成器
在 Python 中,使用了yield语句的函数被称为生成器(generator)。
与普通函数不同的是,生成器是一个返回生成器对象的函数,它只能于进行迭代操作,更简单的理解是 —— 生成器就是一个特殊的迭代器。
在调用生成器运行的过程中,每次遇到yield时函数会暂停并保存当前所有的运行信息,返回yield的值, 并在下一次执行yield方法时从当前位置继续运行。定义一个生成器,很简单,就是在函数中,使用yield表达式代替return语句即可。
举个例子:
现在我们调用 counter()函数,得到的不是一个返回值,而是一个生成器对象:
我们可以把它放到一个 for语句中:
注意:生成器不像列表、元组这些可迭代对象,你可以把生成器看作是一个制作机器,它的作用就是每调用一次提供一个数据,并且会记住当时的状态。而列表、元组这些可迭代对象是容器,它们里面存放着早已准备好的数据。
生成器可以看作是一种特殊的迭代器,因为它首先是 “不走回头路”,第二是支持next()函数:
当没有任何元素产出的时候,它就会抛出一个“StopIteration”异常。
由于生成器每调用一次获取一个结果这样的特性,导致生成器对象是无法使用下标索引这样的随机访问方式
在讲闭包的时候,课后作业留了一道题,就是让大家利用闭包,来求出斐波那契数列。那么同样的题目,我们使用生成器来实现,会有多简单呢?
来,看代码:
只要我们调用 next(f),就可以继续生成一个新的斐波那契数,由于我们在函数中没有设置结束条件,那么这样我们就得到了一个永恒的斐波那契数列生成器,薪火相传、生生不息。
8.2 生成器表达式
其实在前面讲解元组的时候,小甲鱼就给大家预告了这一章节的到来。
因为列表有推导式,元组则没有,如果非要这么写:
那么我们可以看到,它其实就是得到一个生成器嘛:
这种利用推导的形式获取生成器的方法,我们称之为生成器表达式。

函数IX- 递归
递归就是就是函数调用自身的过程,举个例子:
上面代码会持续输出 “AWBDYL”,直到你把 IDLE 关闭或者使用Ctrl + c
快捷键强制中断执行。
加上一个条件判断语句,让递归在恰当的时候进行回归,那么失控的局面就得到了控制:
使用递归求一个数的阶乘
一个正整数的阶乘,是指所有小于及等于该数的正整数的积,所以 5 的阶乘是 1×2×3×4×5,结果等于 120。
我们先来试试迭代的实现方法:
那么递归来实现的话,代码则是像下面这样:
使用递归求斐波那契数列
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。
首几个斐波那契数是:1、 1、 2、 3、 5、 8、 13、 21、 34、 55、 89、 144、 233、 377、 610、 987……
我们先来试试迭代的实现方法:

函数(X)- 汉诺塔
1. 汉诺塔的故事
汉诺塔其实是 1883 年的时候,由法国数学家卢卡斯发明的。不过这个游戏呢,与一个古老的印度传说有关:据说在世界中心贝拿勒斯的圣庙里边,有一块黄铜板,上边插着三根宝针。印度教的主神梵天在创造世界的时候,在其中一根针上从下到上地穿好了由大到小的 64 片金片,这就是所谓的汉诺塔原型。然后不论白天还是黑夜,总有一个僧侣按照下面的规则来移动这些金片:“一次只移动一片,不管在哪根针上,小片必须在大片上面。”另外僧侣们预言,当所有的金片都从梵天穿好的那根针上移到另外一根针上时,世界就将在一声霹雳中消灭,而梵塔、 和众生也都将同归于尽。
2. 汉诺塔玩法分解
对于游戏的玩法,我们可以简单分解为三个步骤:
- 将顶上的 63 个金片从 A 移动到 B
- 将最底下的第 64 个金片从 A 移动到 C
- 将 B 上的 63 个金片移动到 C
看着跟没说一样……
那么先让我们把难度简化为婴儿等级 —— 3 个金片:
- 将顶上的 2 个金片从 A 移动到 B
- 将最底下的第 3 个金片从 A 移动到 C
- 将 B 上的 2 个金片移动到 C
第 2 个步骤仍然是一步到位,难点就在于第 1 和第 3 个步骤,不过难度经过降级之后,我们可以简单看出:
第 1 个步骤只需要借助 C,就可以将两个金片从 A 移到 B,第 3 个步骤只需要借助 A,就可以将 2 个金片从 B 移到 C。
于是:
1. 将顶上的 2 个金片从 A 移动到 B 上,确保大片在小片下方
- 将顶上的 1 个金片从 A 移到 C 上
- 将底下的 1 个金片从 A 移到 B 上
- 将 C 上的 1 个金片移动到 B 上
2. 将最底下的第 3 个金片从 A 移动到 C 上
3. 将 B 上的 2 个金片移动到 C 上
- 将顶上的 1 个金片从 B 移到 A 上
- 将底下的 1 个金片从 B 移到 C 上
- 将 A 上的 1 个金片移动到 C 上
3. 汉诺塔代码实现

参考资料
Python-100-Days
jackfrued • Updated Aug 30, 2023
资料下载
链接: https://pan.baidu.com/s/1G2vDmKz0WQxjY1E7vaUFnA?pwd=a8ir 取码: a8ir 复制这段内容后打开百度网盘手机App,操作更方便哦
- 作者:Conor
- 链接:https://www.xzhh.top/article/python_202301
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。